前回の日記で、利きを入力特徴に加えることで精度が上がることを確認したので、利きを追加したモデルで、初期値から学習をやり直した。
学習データには、elmo_for_learnで深さ8で生成した、1億5千万局面を使用した。
以前に生成したときは、引き分けの局面も出力していたが、引き分けの報酬を0(または1)として学習すると、精度に悪影響があるため、今回は引き分けは出力しないようにした。
iteration単位
ミニバッチサイズ32で、1000iterationごとのtrain loss、test accuracyは以下の通りとなった。
policy networkとvalue networkをマルチタスク学習しているので、test accuracyはそれぞれ求めている。
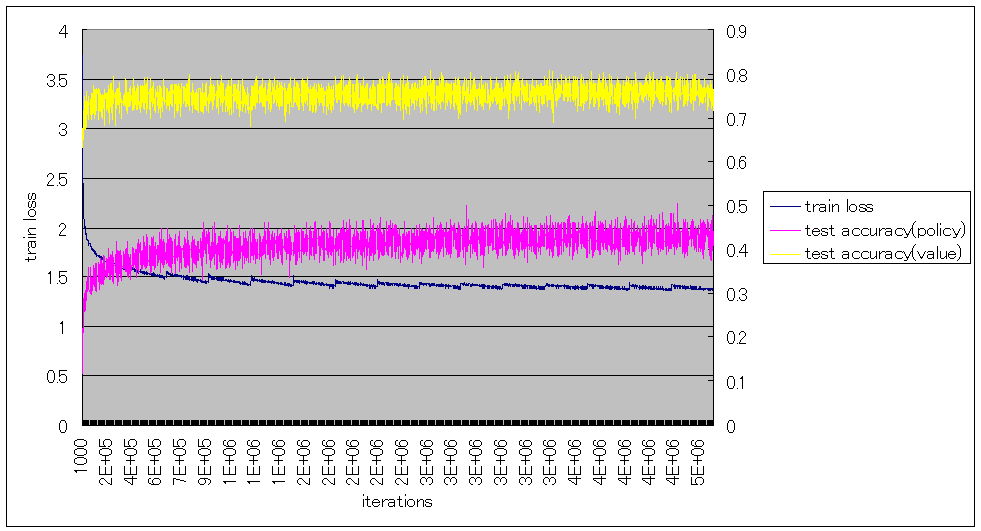
train lossが急に上がっている箇所は、棋譜を1000万局面単位で生成してその単位でソートしているため、局面に偏りが出ているためである。
epoch単位
1000万局面を1epochとした場合、epoch単位では以下の通りとなった。
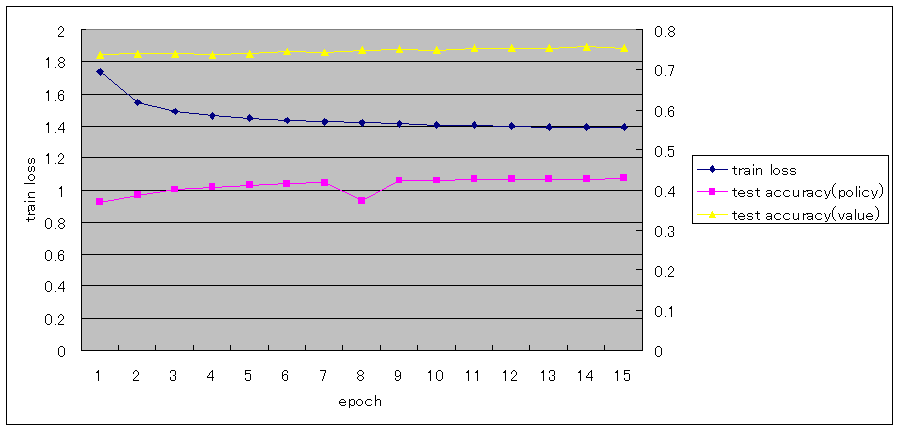
train lossは、まだ減少しているが、ほとんど進まなくなっている。
test accuracy(policy)もまだ増えているが、ほとんど進まなくなっている。
test accuracy(value)は、10epochあたりから0.75から変化していない。
GPSfishと対局
GPSfishと対局すると、GPSfishが劣勢と判断している局面でも優勢と判断しており、かなり遅れてマイナスとなっている。
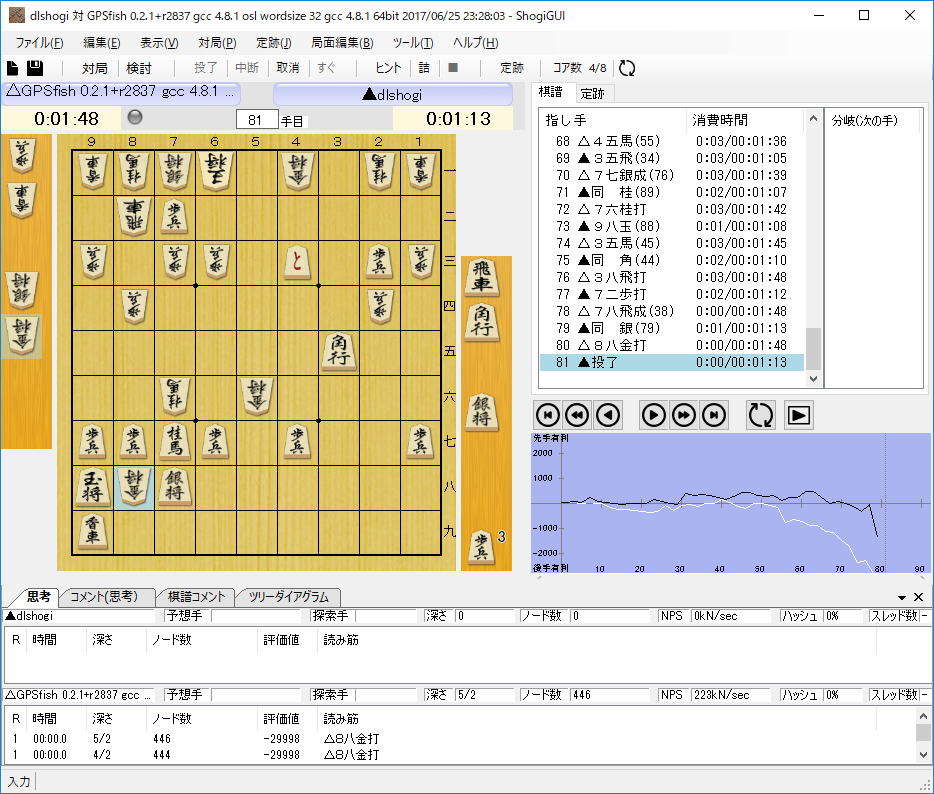
バリューネットワークが勝敗がはっきりするまで局面を正しく学習できていないようである。
バリューネットワークは、局面の勝率を学習するため、似た局面での勝ち、負けのデータが十分な量必要になる。
1億5千万局面では不十分と思われる。
バッチサイズ変更
勝率は確率的な事象であるため、バッチサイズが小さいと学習できない可能性があるため、バッチサイズを変えて学習してみた。
16epoch目をミニバッチサイズを変えて学習した場合の、train lossとtest accuracyは以下の通りとなった。
| ミニバッチサイズ | train loss1 | train loss2 | train loss | test acc.(policy) | test acc.(value) |
| b=32 | 0.9122 | 0.4522 | 1.3644 | 0.4301 | 0.7569 |
| b=64 | 0.9102 | 0.4592 | 1.3694 | 0.4362 | 0.7604 |
| b=128 | 0.8997 | 0.4672 | 1.3669 | 0.4377 | 0.7626 |
| b=256 | 0.8997 | 0.4683 | 1.3680 | 0.4386 | 0.7620 |
| b=512 | 0.8998 | 0.4684 | 1.3683 | 0.4380 | 0.7620 |
| b=1024 | 0.9049 | 0.4719 | 1.3769 | 0.4371 | 0.7609 |
loss1は指し手(policy network)の損失、loss2は勝率予測(value network)の損失を示す。
b=32がtrain lossが一番低くなっているが、test accuracyは一番悪くなった。
b=256がtest accuracy(policy)が最も高い。test accuracy(value)は、b=128が最も高いが、b=256,512もほぼ同じである。
よって、b=256を採用することにする。
学習時間もb=32では1000万局面で1:56:08だったが、b=256にすることで1:15:18と短くなる。
ブートストラップ
elmo_for_learnで生成したデータには、局面の探索結果の評価値が含まれている。
バリューネットワークの値をその評価値に近づけるように学習することで、学習の効率を上げることができないか試した。
このように別の推定量を用いてパラメータを更新する手法をブートストラップと呼び、elmoでも用いられている。
また、数手先の探索の評価値を用いるため、TD学習とも呼ばれる。
理論的には理由が明らかにされていないが、経験的にブートストラップ手法は、非ブートストラップ手法より性能が良いことが知られている。
| train loss1 | train loss2 | train loss3 | test acc.(policy) | test acc.(value) | |
| ブートストラップなし(b=128) | 0.9031 | 0.4620 | 0.5077 | 0.4377 | 0.7628 |
| ブートストラップあり(b=128) | 0.9007 | 0.4744 | 0.4466 | 0.4370 | 0.7621 |
train loss3はブートストラップ項の損失で、バリューネットワークの値と探索結果の評価値をシグモイド関数で勝率に変換した値との交差エントロピーを示す。
ブートストラップ項の損失には係数を掛けている。
train loss3は下がっているので、評価値に近づいているが、test accuracy(value)はほとんど変わっていない。
この測定だけでは、効果があるか不明である。
一旦採用しないで学習を進めることにする。