前回の続き。
tadaoyamaoka.hatenablog.com
前回訓練損失が下がるところまで確認したが、正解率は0%のままだった。
その後学習を継続し、126,504ステップ時点で、訓練損失と正解率は以下の通りとなった。
学習結果
訓練損失

正解率
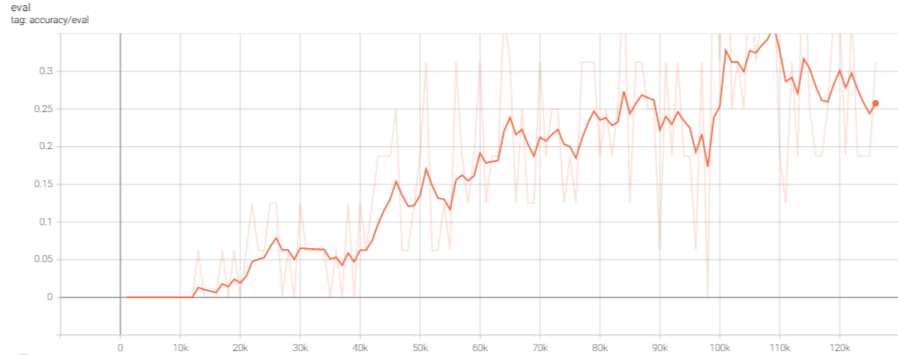
floodgateの棋譜に対する、正解率も約25%まで上昇している。
バッチサイズは32のため、学習した局面は4,048,128局面である。
拡散モデルでも、将棋の方策を学習できることが確認できた。
ResNetとの比較
ResNet30ブロック384フィルタのモデルを同じ局面数だけ学習した場合、正解率は約37%になる。
拡散モデルの方が学習に時間がかかっている。
2023/07/16 17:27:24 INFO epoch = 1, steps = 4000, train loss = 2.1729847, 0.5884042, 0.5848547, 2.7602069, test loss = 2.0987635, 0.5968569, 0.6581656, 2.7160361, test accuracy = 0.3750000, 0.6640625
訓練時間
10kステップの学習に約1時間かかっている。

ResNet30ブロック384フィルタのモデルでは、バッチサイズ1024で同じ局面数した場合にかかる時間は、2分25秒である。
拡散モデルの学習は25倍近く時間がかかる。