ConvNeXtは、ResNetなどの畳み込みニューラルネットワークで構成されるニューラルネットワークで、SwinTransformerなど最先端のVisionTransformer系モデル並みの性能が出せるというモデルである。
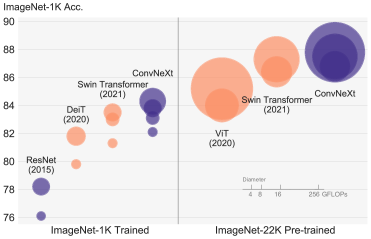
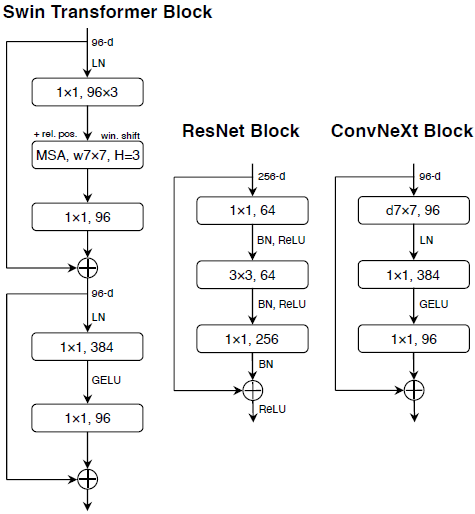
モデル構成
残差ブロックの1層目がカーネルサイズ7x7のDepthWiseConvになって、2層目、3層目がPointWiseConvになる。
BatchNormの代わりにLayerNormを使用して、1層目の後のみにする。
活性化関数をGELUにして、2層目の後のみにする。
dlshogiで試す
dlshogiでConvNeXtを試してみた。
精度は、ResNet15ブロック+活性化関数Swishのモデルと比較した。
画像サイズが9x9のため、DepthWiseConvのカーネルサイズ7x7が大きいため、5x5と3x3でも試した。
残差ブロックの入力のチャネル数は、論文では96(対応するResNetは256)だが、比較対象のResNetが224のため、84とした。
活性化関数をReLUとした場合も比較した。
訓練データには、dlshogiの20ブロックで生成した9.4千万局面(同一局面を平均化すると7千万局面)を使用した。
テストデータにfloodgateのR3500以上の棋譜からサンプリングした856,923局面(重複なし)を使用して評価した。
実装
論文の実装では、LayerNormをPermuteでchannels_lastにして実装していたが、GroupNorm(1, channels)で実装した。
実験条件
- バッチサイズ 4096
- 学習率 0.04、1エポックごと半減
- エポック数 4
- 平均化あり、評価値補正あり
- AMPあり
実験結果
| カーネル | 活性化関数 | 方策損失 | 価値損失 | 方策正解率 | 価値正解率 | |
| ResNet | 3x3 | Swish | 1.61430365 | 0.510782225 | 0.478344475 | 0.729585625 |
| ConvNeXt | 3x3 | GELU | 1.8290839 | 0.5681706 | 0.4311009 | 0.6908397 |
| ConvNeXt | 5x5 | GELU | 1.7987399 | 0.5582815 | 0.4365024 | 0.7007689 |
| ConvNeXt | 7x7 | GELU | 1.783808 | 0.5708612 | 0.4398117 | 0.6815857 |
| ConvNeXt | 3x3 | ReLU | 1.8311639 | 0.5632808 | 0.4303452 | 0.6977831 |
考察
ConvNeXtよりもResNetの方が精度が良い。
ConvNeXtのカーネルサイズは、5x5の精度が高い。しかし、学習時間は一番かかっている。
活性化関数は、GELUの方がReLUに比べて、方策の精度が上がったが価値の精度は下がっている。
まとめ
dlshogiでConvNeXtを試した。
ResNetの方が良いことが分かった。
画像では効果的なモデルだが、将棋には有効ではなさそうである。