昨日開催された電竜戦(予行演習3)にdlshogiも参加し、結果は34チーム中4位でした。
第1回コンピュータ将棋オンライン 電竜戦予行演習3 勝敗表
DL勢同士の対局
CrazyShogi
CrazyShogiのとの対局は、危なげなく勝ちました。
第1回電竜戦 棋譜中継(単一棋譜)
AobaZero
AobaZeroとの対局は、後手番で80手くらいで評価値400くらい劣勢になっていました。
その後、AobaZeroに読み抜けがあったのか、dlshogiが徐々に優勢になって勝ち切りました。
第1回電竜戦 棋譜中継(単一棋譜)
AobaZeroの序盤はかなり強そうです。
dlshogiは初期局面集を使用しているため序盤の局面はあまり学習していないこと、モデルのサイズが小さいこと、AobaZeroの方が学習リソースが多いことなどが、序盤の強さに影響していそうです。
序盤に対しては、改善が必要そうなので検討することにします。
使用したモデル
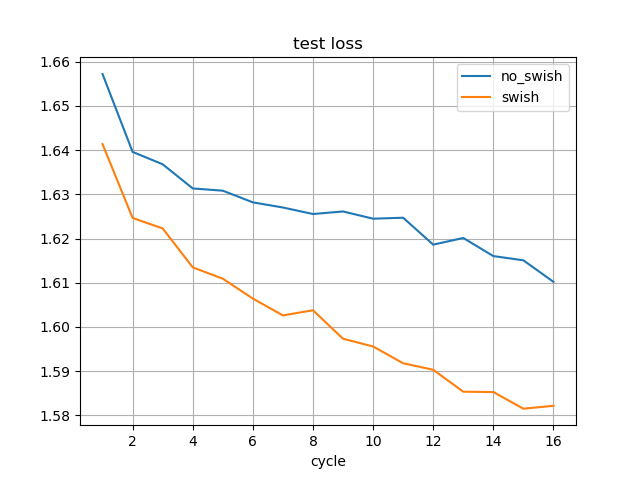
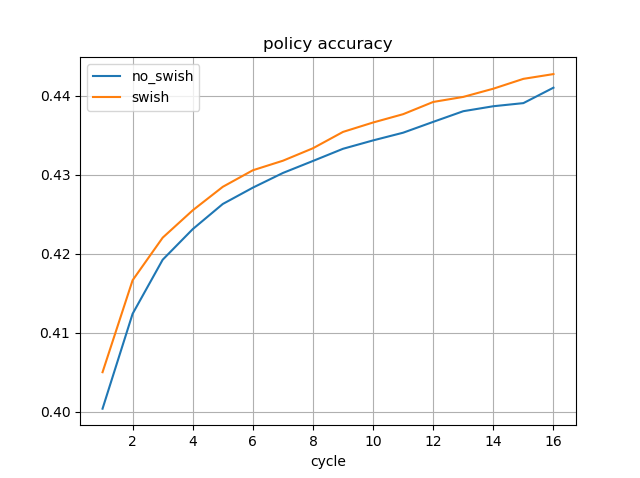
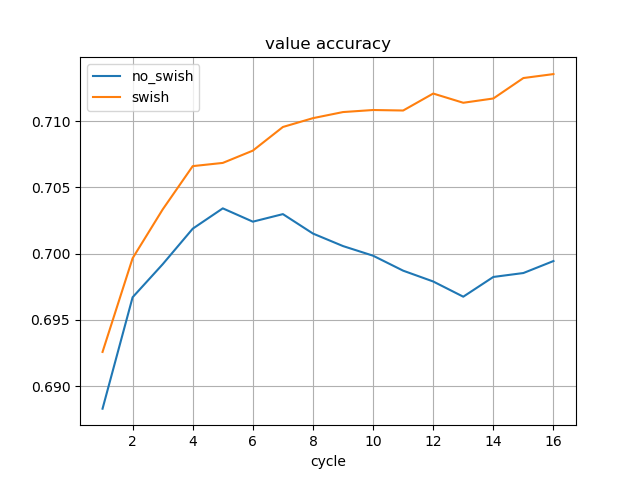
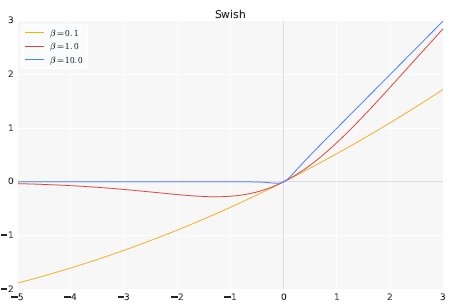
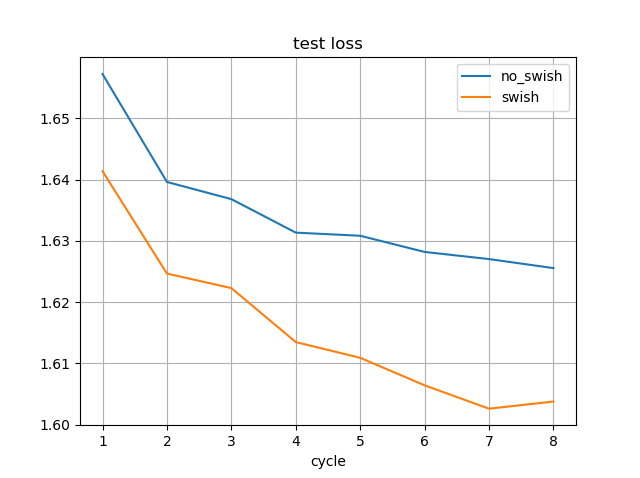
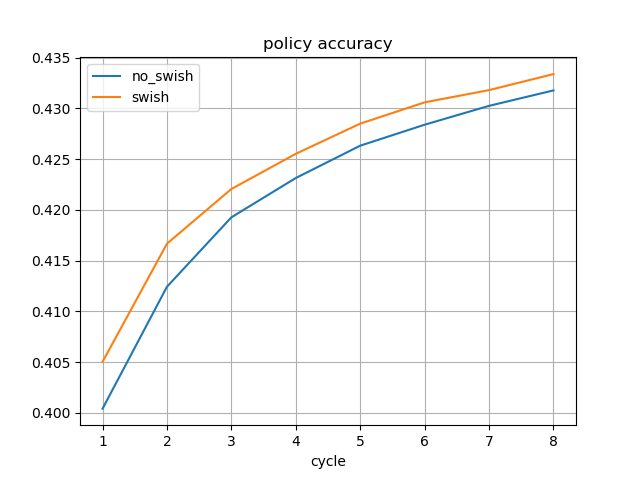
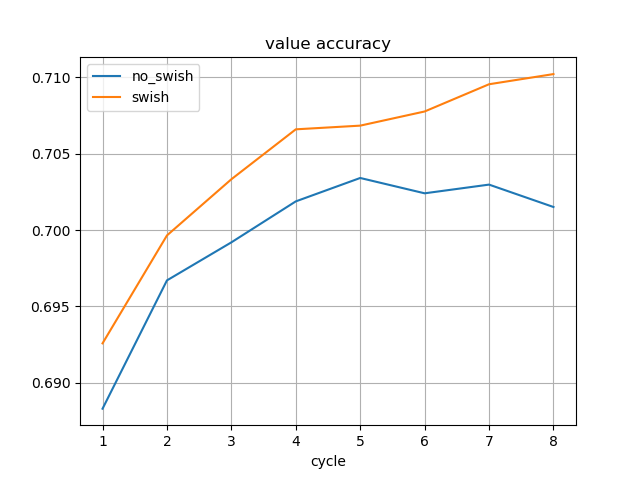
学習途中のSwishのモデルを使用しました。
過去のdlshogiの強化学習で生成した局面を学習させています。
2018年から開始して、390サイクルまで強化学習を行っていますが、途中で条件変更やバグ修正、改良を行っているため、あまりに古い局面は質が良くないため、2020年から開始したリーグ戦で生成した200サイクル目以降の局面を学習させています。
水匠2 1000万ノード固定に対する強さは、Swishなしの最新のモデルよりも高くなっています。
# PLAYER : RATING ERROR POINTS PLAYED (%) CFS(%) W D L D(%) 1 normal10_swish_341 : 39.5 43.1 139.0 250 56 58 133 12 105 5 2 wideresnet10_selfplay_387 : 32.8 48.1 105.5 193 55 59 101 9 83 5 3 normal10_swish_326 : 25.8 34.6 278.5 500 56 51 268 21 211 4 4 normal10_swish_337 : 25.3 42.3 134.0 250 54 88 130 8 112 3 5 YaneuraOu NNUE 4.91 64AVX2BMI2 : 0.0 ---- 851.0 1693 50 98 817 68 808 4 White advantage = 17.19 +/- 7.79 Draw rate (equal opponents) = 4.20 % +/- 0.46
※wideresnet10_selfplay_387がSwishなし
※normal10_swish_xxxが200サイクル以降の局面を学習させたSwishのモデル、数値は何サイクル目までのデータを学習したか
※秒読み3秒
ただし、直接対局させると、最新のSwishなしのモデルの方が強いです。
# PLAYER : RATING ERROR POINTS PLAYED (%) CFS(%) W D L D(%) 1 wideresnet10_selfplay_387 : 0.0 ---- 66.0 114 58 96 61 10 43 9 2 normal10_swish_346 : -56.0 61.6 48.0 114 42 --- 43 10 61 9 White advantage = 18.94 +/- 32.96 Draw rate (equal opponents) = 8.91 % +/- 2.69
生成した局面をすべて学習しきった後には、上回ることを期待しています。
20ブロック+256フィルタ+Swishのモデルも学習しており、そちらも強くなれば候補になります。
Resnetの構成の変更
dlshogiでは、過去の経緯により、あまり検証を行わずにResnetの構成をpre-activation構成にしていました。
今回学習し直す際に、オリジナルのResnet構成も学習させたところ、floodgateの棋譜に対する精度は高くなるようです。
まだ検証が十分にできていないので、別途検証する予定です。
今回は、オリジナルのResnet構成の方を使用しました。
本番大会に向けて
Swishのモデルを、最新のサイクルまで学習させることで、予行演習よりも強くできると期待しています。
dlshogiは、やねうら王ライブラリのソフトとも十分戦えるようになってきています。
しかし、トップとはfloodgateではレート差400近くあるので、まだ改良は必要だと思っています。
ハードウェア面では、いつから提供されるかは不明ですが、クラウドでA100が使用可能になればTensorCoreでINT8が使用できるようになるため、NPSが数倍になりそうという期待があります。
少なくとも電竜戦には間に合わなそうです。
最後に、電竜戦(予行演習3)に参加された皆様、運営の皆様、お疲れ様でした。