先日試したSwishについて、推論速度がどれくら低下するのかと、精度が上がった代わりに速度が低下した場合に強さにどう影響するのかが気になったので調べてみた。
精度
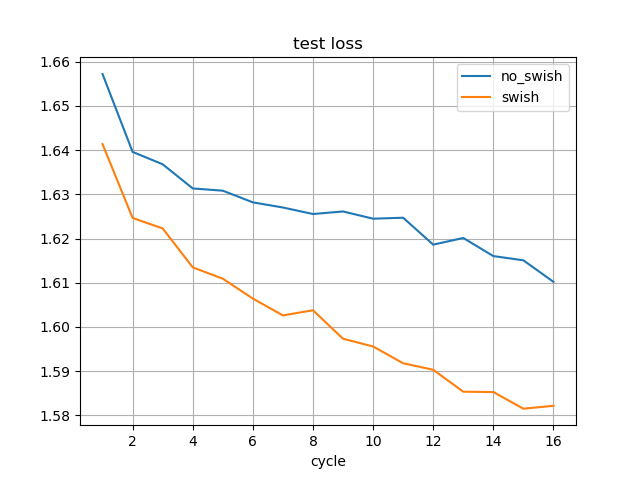
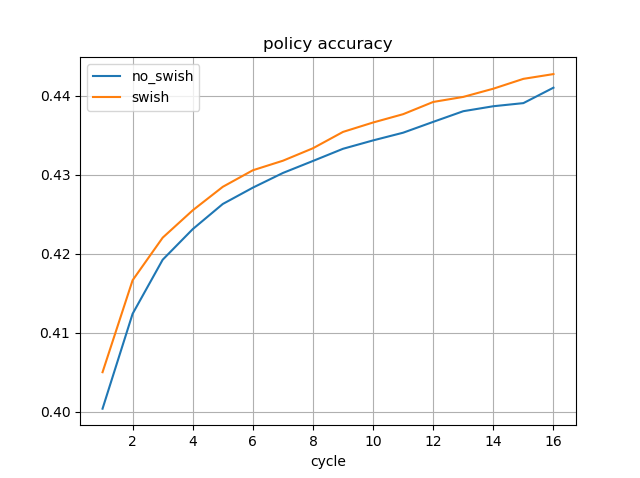
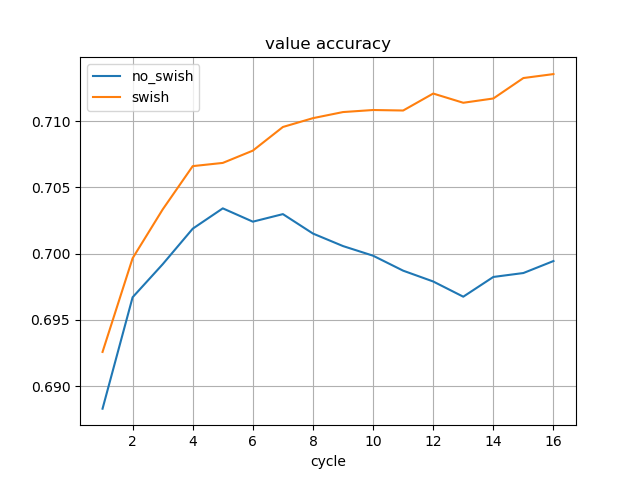
先日は、8サイクル分学習した時点の結果を記したが、今回は16サイクル分学習したモデルを使用した。
16サイクル分学習した時点の精度は以下の通り。
| 条件 | 訓練損失平均 | テスト損失 | policy一致率 | value一致率 |
|---|---|---|---|---|
| Swishなし | 0.84661563 | 1.61019968 | 0.44103022 | 0.69944063 |
| Swishあり | 0.86657027 | 1.58214659 | 0.44275271 | 0.71354634 |
推論速度
floodgateの棋譜からサンプリングした100局面に対して、5秒思考した際のNPSを計測した。
測定プログラム:
https://github.com/TadaoYamaoka/DeepLearningShogi/blob/master/utils/benchmark.py
V100 1枚で、Onnx出力してTensorRTを使用。
| Swishなし | Swishあり | |
|---|---|---|
| 平均 | 34926.01 | 30477.17 |
| 中央値 | 37064 | 32797 |
| 最小値 | 17572 | 17036 |
| 最大値 | 41434 | 34941 |
NPSは、平均で87.3%に低下している。
強さの測定
互角局面集を使用して、先後を交互に入れ替え、250戦行った結果で測る。
引き分けも考慮するため、勝率は、勝ちを1ポイント、引き分けを0.5ポイントとして、ポイントの合計/250で計算する。
1GPU、秒読み1秒で、250対局行った結果は以下の通り。
ReLUを途中からSwishに変更できるか
Swishにすることで、同一データの学習で強くなることが確認できたが、現在学習済みのモデルのReLUをSwishに変更できるか検証してみた。
最新の1サイクル分だけ、ReLUをSwishに変更して学習した場合
373サイクル学習したモデルに対して、374サイクル目のデータをReLUをSwishに変更して学習してみた結果は以下の通り。
| 条件 | 訓練損失平均 | テスト損失 | policy一致率 | value一致率 |
|---|---|---|---|---|
| Swishなし | 0.69250407 | 1.6051037 | 0.46532138 | 0.72403891 |
| Swishあり | 0.92641119 | 1.51048969 | 0.44681778 | 0.71891699 |
精度が大幅に低下している。
ReLUで学習したモデルはReLUで最適化されているため、Swishに変更することはできなそうだ。
過去5サイクル分まで遡って、同一データを学習した場合についても比較してみた。
| 条件 | 訓練損失平均 | テスト損失 | policy一致率 | value一致率 |
|---|---|---|---|---|
| Swishなし | 0.69250407 | 1.6051037 | 0.46532138 | 0.72403891 |
| Swishあり | 0.76547083 | 1.52928974 | 0.46177364 | 0.72609071 |
policyの一致率は少し足りていないが、valueの一致率はReLUを上回っている。
十分にファインチューニングを行えば、既存のReLUのモデルをSwishに変更することはできそうということがわかった。