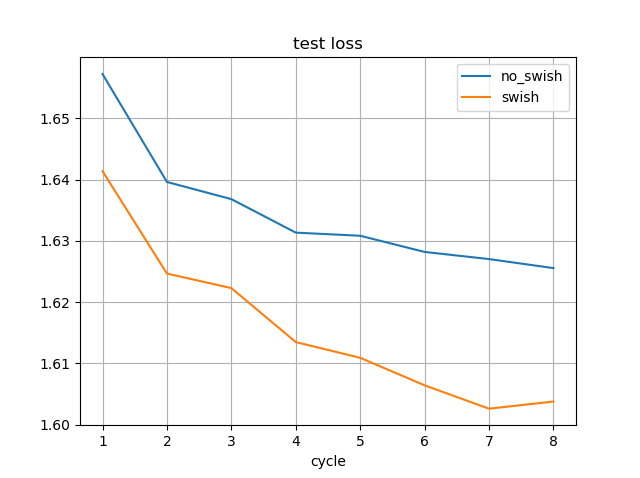
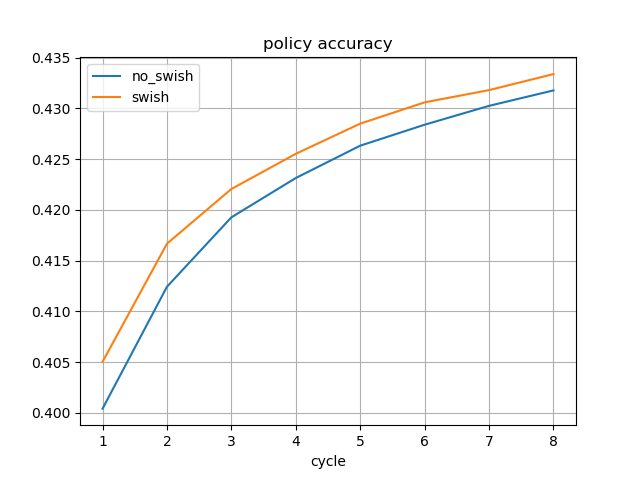
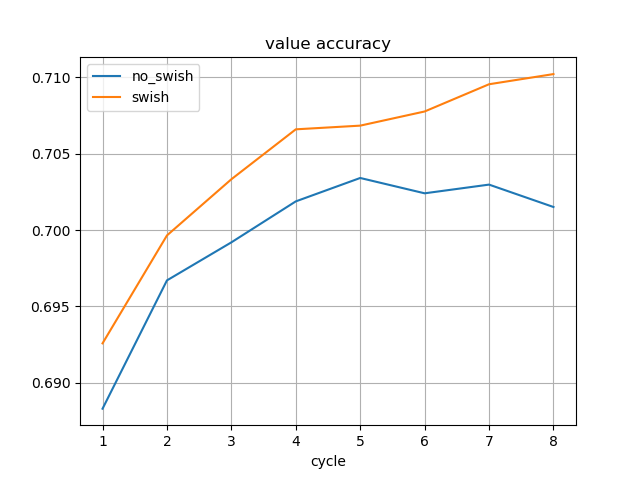
画像認識で高い精度を達成しているEfficientNetで使われている活性化関数Swishが将棋AIでも効果があるか試してみた。
EfficientNetでは、残差ブロックにMBConvというアーキテクチャが使用されており、その中の活性化関数にSwishが使用されている。
MBConvについても別途検証を行ったが、今回はSwishの効果について記す。
Swishについて
Swishは以下の式で定義される活性化関数である。
ここで、はシグモイド関数
である。
グラフの形は以下のようになる。
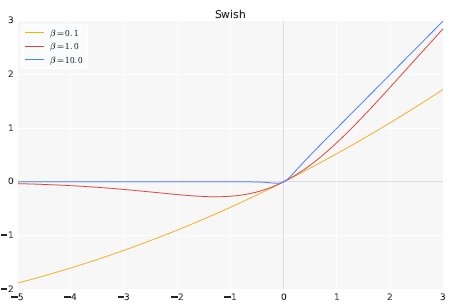
どのような場合でもReLUに代わるものではないが、多くのタスクでReLUよりも精度が向上することが報告されている。
PyTorchのSwish実装
GitHubで公開されているPyTorchのEfficientNetの実装からSwishのコードを流用した。
この実装では、微分の計算が効率化されている。
ただし、Onnxに出力する際はエラーになるようなので、オリジナル実装に切り替える必要がある。
dlshogiのネットワークへの適用
dlshogiのpolicy_value_network.pyのreluをswishに置き換えたソースがこちら。
DeepLearningShogi/policy_value_network_swish.py at feature/experimental_network · TadaoYamaoka/DeepLearningShogi · GitHub