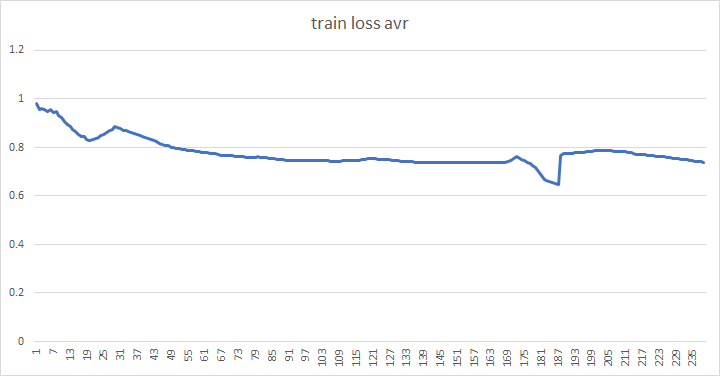
dlshogiの10ブロックのWideResnetの自己対局による強化学習を続けていましたが、230サイクルほどでほぼ頭打ちになりました。
訓練損失は下がり続けていますが、floodgateの棋譜に対する損失が上昇傾向になっており、技巧2のとの勝利も上がらないため、このモデルでの強化学習は打ち切ることにしました。
技巧2(4コア CPU)との勝率は、GPU2080Ti1枚、1手3秒で32%程です。
訓練損失
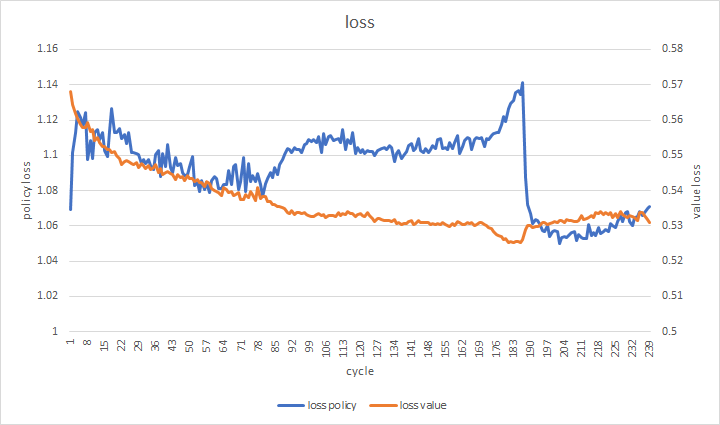
floodgateの棋譜に対する損失
floodgateの棋譜に対する正解率
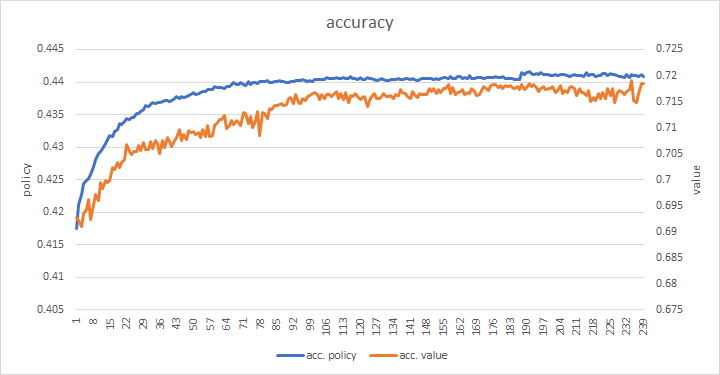
188サイクルあたりで訓練損失が急に下がって、floodgateの棋譜に対する損失が上昇したため、189サイクル目からはエントロピー正則化とL2正則化を加えるようにしました。
少しだけ精度が上がりましたが、すぐにほぼ横ばいになりました。
このあたりが、このモデルの強化学習の限界のようです。
SENetのモデルの学習開始
以前に将棋AIでもSENetが有効であることを実験で確かめたので、SENetのモデルで強化学習を始めることにしました。
今回も、教師ありで事前学習を行ってから、自己対局で強化学習を行う予定です。
教師データはWCSC29のAperyで生成した5億局面を使用します。
WCSC29のAperyは学習局面のフォーマットに手数が追加されていましたが、以前と同じフォーマットで生成しました。
終局近くの手順も学習したいため、対局終了の閾値は、30000としました。
引き分けも生成します。
SENetの実装
ChainerでのSENetの実装は、以前に記事にしたものと同じです。
対局時の推論処理は、cuDNNで実装しているため、cuDNNを使って実装しました。
cuDNNのAPIはChainerよりも使える機能が少ないため、どのAPIで実現できるかを調べるのに結構苦労しました。
global average poolingは、averagePooling2Dのwindowを盤面のサイズにすることで実現しました。
Squeezeの結果とチャンネルごとの積は、cudnnOpTensorのCUDNN_OP_TENSOR_MULモードで実現できました。
(FP16の場合でも計算はfloatなので、係数のalphaとbetaもfloatにする必要があることに気付かず、何時間もデバッグしていましたorz)
cuDNNで実装したい人はほとんどいないと思いますが、ソースを公開しました。
https://github.com/TadaoYamaoka/DeepLearningShogi/blob/master/usi/nn_senet10.cpp
学習結果
Aperyで生成した5億局面で学習した結果、floodgateの棋譜に対する損失と正解率は以下の通りです。
エントロピー正則化とL2正則化は、はじめから加えています。
WideResnet10ブロックをelmoで生成した4.9億局面で学習した際も比較のために載せておきます。
| WideResnet | SENet | |
|---|---|---|
| policy loss | 0.93350023 | 0.9108452 |
| value loss | 0.58716744 | 0.57989293 |
| policy accuracy | 0.4090266 | 0.415206 |
| value accuracy | 0.68762606 | 0.68894225 |
教師データの違いがあるため単純に比較できませんが、精度は上がっています。
技巧2に対する勝率
事前学習したモデルで技巧2(CPU 4コア)に対する勝率を測りました。
1手3秒で100回対局した結果は11-1-88で、勝率11%となりました。
WideResnet10ブロックのモデルで事前学習のみでは技巧2には全く勝てなかったため、技巧2に勝率11%は思ったより良い結果です。
このモデルをベースに、自己対局による強化学習を開始する予定です。
少なくともGPU1枚で技巧2を超えるようになってほしいと思っています。