前回、軽量価値ネットワークの推論をStockfishの探索に組み込んで、モデルサイズ相当のNPSで探索できることを確認した。
前回は、36,819,741局面を8エポック学習しただけで、Lesserkaiに勝てるがGPSFishには勝てなかった。
今回は、dlshogiの学習で使用した約37億局面を使用して、2日程度学習させてみた。
学習データ
dlshogiの学習で使用した約37億局面を使用する。
dlshogiの自己対局棋譜とdlshogiとNNUEの対局棋譜が含まれる。
NNUEの学習では、静止探索した後の局面を学習に使用するが、今回は特に前処理は行わない。
学習条件
dlshogiの学習では、訓練データを使い切る単位を1エポックとしているが、1エポックの間に学習率を下げないと過学習が起きたので、訓練スクリプトにsteps_per_epochというオプションを追加し、仮想的なエポックの単位で学習率を下げるようにした。
学習設定は以下の通り。
- steps_per_epoch : 16000
- (仮想)エポック数 : 100
- 学習率スケジューラ: ReduceLROnPlateau(factor=0.5,patience=5)
- 初期学習率: 0.01
- オプティマイザ : Adam(weight_decay=1e-4)
- バッチサイズ : 16384
訓練データを使い切る単位を1エポックにした場合、7エポック分に相当する。
強さ
前回勝てなかったGPSFish相手に勝てることを確認した。
8スレッド、秒読み3秒、初期局面から
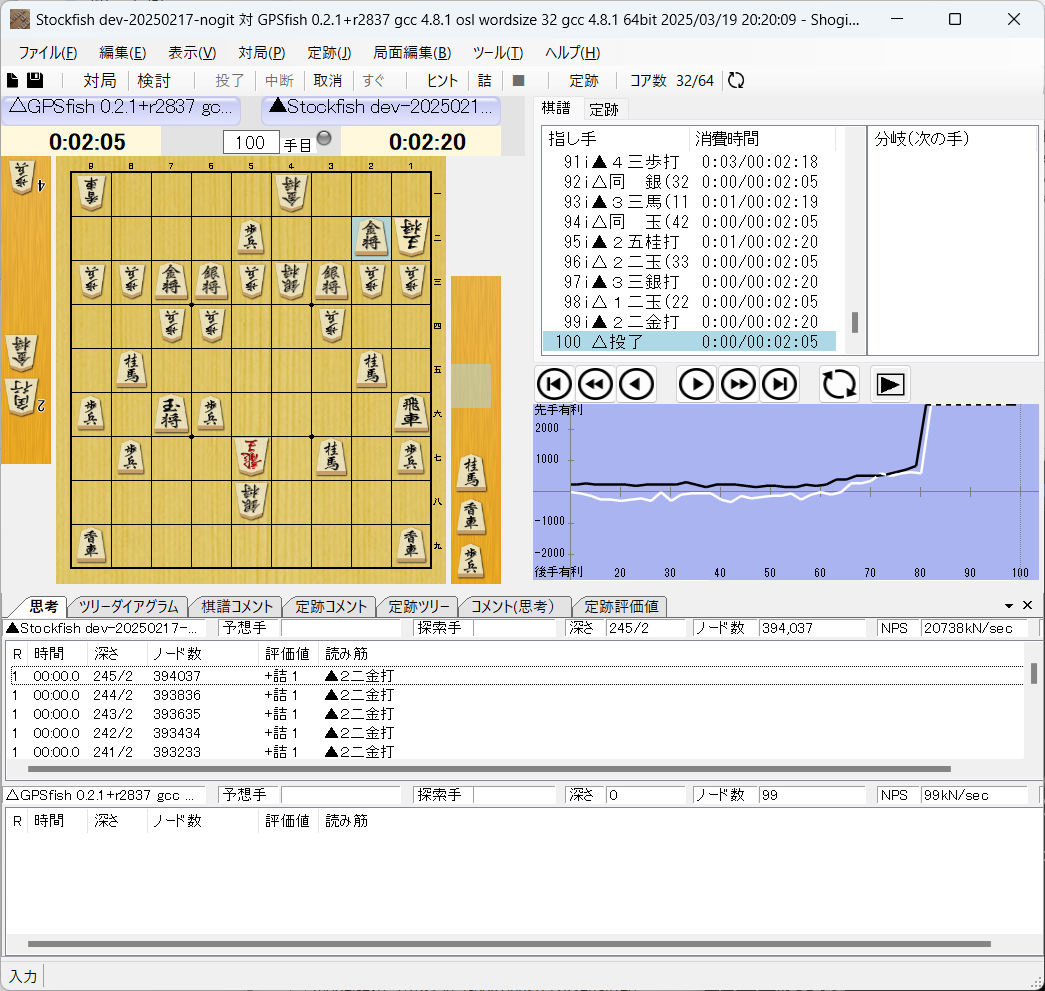
水匠5相手には、まだ勝てなかった。

まとめ
軽量価値ネットワークを、dlshogiの訓練データを流用して2日程度学習させた。
結果、GPSFishには勝てるようになったが、水匠5にはまだ勝てなかった。
NNUE系の学習には80億面くらい使用されているため、まだ学習が不足していそうである。
次は、tanuki-の公開されている80億局面の評価値をdlshogiで付け直して学習してみたい。