AlphaGoの論文ではSL policy networkは13層のCNNとなっているが、画像認識の分野では単純なDCNNよりGoogLeNet(Inception)やResidual Network(ResNet)が高い精度を上げている。
ResNetで層を増やすのが最も精度が上がるが、層が増えるほど学習時間も増える。
ResNetはカーネルサイズ、フィルター枚数を少なくして層を増やす、狭く深くという方向だが、ResNetと同じ構造で、層を浅くしてカーネルサイズ、フィルター枚数を増やしたものに、Wide Residual Networksがある。
学習時間が増えない方が個人としては望ましいので、Wide Residual Networksを試してみた。
Wide Residual Networks
ResNetは、以下のように2層の畳み込みのブロックとショートカットを足し合わせ、それを複数繋げることで構成する。
Wide ResNetはブロックの2層の畳み込みの間でDropoutを行うことが特徴である。
畳み込み層のバイアスはなしにする。
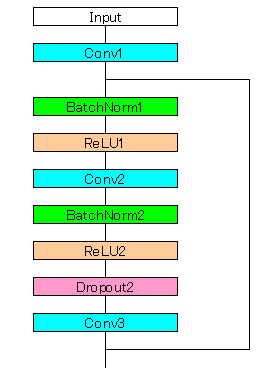
13層のCNNをWide ResNetの構成にすると畳み込み層が一つ余るので、1層減らして12層(5ブロック)で構成した。
測定結果
前回の13層のCNNと12層のWide ResNetを比較すると以下のようになった。
カーネルサイズ(3×3)、フィルター枚数(256)は変更していない。

Wide ResNetの方が収束が速くなっている。
3エポック回しているので、3エポック目ではtest accuracyがほぼ同じになっているが、1エポックで比較すると精度も高い。
学習時間は以下の通りとなった。(422852局面、3エポック)
| 学習時間 | |
| 13層CNN | 0:48:24 |
| Wide ResNet | 0:48:44 |
学習時間はわずかに増えた。
畳み込み層は1層減ったがショートカットを足し合わせる演算が影響していると思われる。
GitHubにソースを公開しました。
github.com