深いResNetの訓練では、勾配爆発が起きる。そのため、Batch Normalizationを使用するのが一般的である。
Leela Chess Zeroでは、Batch Normalizationの統計情報に関連する問題が報告されている。
Pawn promotion issues in T40 · Issue #784 · LeelaChessZero/lc0 · GitHub
具体的には、訓練時の正規化はバッチ単位で行われるのに対して、推論時は訓練時の移動平均が使用されるため、頻度の少ない局面では、推論時にチャネルの出力が0になるケースがあるという問題である。
将棋でもそれに該当する具体的な局面があるかは調べられていない。
Leela Chess Zeroでは、Batch Renormalizationを採用することで、対処を行っている。
Test40 update - Leela Chess Zero
一方、KataGoでは、Batch Normalizationを使用するのをやめて、Fixup Initializationを採用している。
KataGo/KataGoMethods.md at master · lightvector/KataGo · GitHub
Fixup Initializationは、適切な初期値を設定することで、Batch Normalizationがなくても勾配爆発を解消するという手法である。
詳しい理論は、論文を参照いただくとして、以下の通りResNetを変更して、初期値を設定を行う。
- 分類レイヤーと各残差ブランチの最後のレイヤーを0に初期化する。
- 標準的な方法(He et al.(2015)など)を使用して1つおきのレイヤーを初期化し、残りのブランチ内のウェイトレイヤーのみを
でスケーリングする。
- すべてのブランチにスカラー乗数(1で初期化)とスカラーバイアス(0で初期化)を、各畳み込み、線形、および要素ごとのアクティブ化レイヤーの前に追加する。
重要なのは、2.で、1.、3.は訓練のパフォーマンスを向上する。
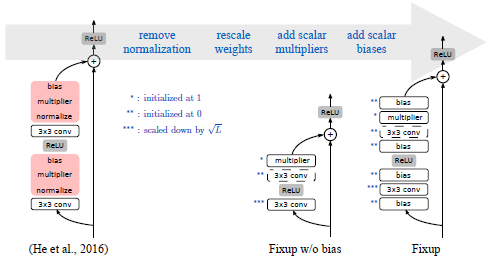
論文では、CIFER-10とImageNet、翻訳タスクでの実験結果が報告されており、CIFER-10とImageNetでは、Batch Normalizationより若干精度が下回っているが、KataGoでは、Batch Normalizationと同等のパフォーマンスを再現できたそうだ。
Batch Normalizationがなくなると訓練速度を大幅に向上できるため、dlshogiでもFixup Initializationの効果があるか試してみた。
実装
論文著者によるPyTorchの実装を参考にした。
GitHub - hongyi-zhang/Fixup: A Re-implementation of Fixed-update Initialization
始めswishのモデルに適用したら、まったく学習できなかった。
活性化関数は、ReLUである必要があるようだ。
論文は出力層の全結合の重みとバイアスを0で初期化するとあるが、policyとvaueの出力層にも畳み込みがあるため、それらを0で初期化したところ、valueが全く学習できなかった。
そこで、出力層はvalueの最終層の全結合のみ0で初期化した。
測定方法
dlshogiの強化学習で生成した60,911,062局面で訓練し、floodagteからサンプリングした856,923局面でテストした。
MomentumSGD、学習率0.01、WeightDecay0.0001でResNet10ブロックのネットワークを訓練した。
結果
訓練損失
| 訓練平均方策損失 | 訓練平均価値損失 | |
|---|---|---|
| Batch Normalization | 0.68084329 | 0.38440849 |
| Fixup Initialization | 0.70152103 | 0.39291802 |
テスト損失
| テスト方策損失 | テスト価値損失 | |
|---|---|---|
| Batch Normalization | 0.97448369 | 0.54640203 |
| Fixup Initialization | 0.97963965 | 0.54785213 |
テスト正解率
| テスト方策正解率 | テスト価値正解率 | |
|---|---|---|
| Batch Normalization | 0.42880582 | 0.70676383 |
| Fixup Initialization | 0.42871940 | 0.70434300 |
考察
Fixup Initializationでも、安定して学習できることが確認できた。
Batch Normalizationと比較すると、精度は落ちている。
収束するまで学習した場合に、どうなるかまでは確認できていない。
まとめ
Batch Normalizationをなくすと訓練速度を大幅に短縮できるというメリットがあるため、dlshogiの学習でFixup Initializationの効果があるか試してみた。
結果、Fixup Initializationで安定して学習できることが確認できた。
しかし、Batch Normalizationと比べると少し精度が落ちることがわかった。
収束するまで学習した場合や、対局しての強さについては別途確認したい。