ここ数週間、探索部の細かい改良をしては測定していた。
小さなレーティング差を計測するには多くの対局数が必要になるので、一つの改良の確認に時間がかかるのがつらいところである。
1手1秒と1手3秒で結果が異なることもあるため、長時間思考で強くしたいため1手3秒での測定を基本にしている。
測定は、変更前後の自己対局と、水匠2 2スレッド1000万ノードとの対局(dlshogiは1GPU3スレッド)で確認している。
水匠2との対局は、対局数が少ないと誤差が大きくでるので、500対局以上でないと信用できない。
以下に、行った変更と測定結果をまとめておく。
1.ノード管理の変更
以前に、メモリ節約のために子ノードへのポインタと統計情報を、ノードに訪問するまで初期化しない対応を行ったが、弱くなったため不採用とした。
これを、子ノードへのポインタのみ親ノードで配列で管理し初期化のタイミングを遅らせて、統計情報の管理は今まで通りにするようにした。
以前に弱くなった理由は、子ノードのpolicyの値と、統計情報のメモリ配置が分散してしまったことだと考えたので、policyの値と統計情報はメモリ上で連続になるようにした。
また、ノード展開を排他制御するため、各ノードでmutexを保持していたが、これがノードごとに(VC++の場合)80バイト消費するので、固定サイズ65536だけmutexを確保して、各局面のハッシュの下位ビットをインデックスとして使用して利用するようにした。
これは、KataGoでもmutex_poolの仕組みとして採用されていたが、配列のインデックスをランダムに割り当ててノードにインデックスを保持する実装になっていた。
インデックスはノードに保持しなくても、探索中の局面のハッシュから導出した方がメモリの節約になる(←Discordでのやねうら氏からの指摘)。
測定結果
# PLAYER : RATING ERROR POINTS PLAYED (%) CFS(%) W D L D(%)
1 dlshogi : 1.5 11.9 383.0 760 50 60 340 86 334 11
2 new_node_manage : -1.5 11.9 377.0 760 50 --- 334 86 340 11
# PLAYER : RATING ERROR POINTS PLAYED (%) CFS(%) W D L D(%)
1 dlshogi : 5.2 22.6 275.5 542 51 65 267 17 258 3
2 YaneuraOu NNUE 5.32 64AVX2 : -0.6 13.9 535.5 1074 50 60 519 33 522 3
3 new_node_manage : -4.6 22.6 263.0 532 49 --- 255 16 261 3
少し弱くなるようだが、5000万ノード(V100×8で約4分)探索した際のメモリ使用量は、86,880,520KBから79,180,824KB(91.1%)になった。
採用するか悩ましいが、勝率の型をfloatからdoubleにした場合にさらにメモリを消費することを考慮して、採用するつもりである。
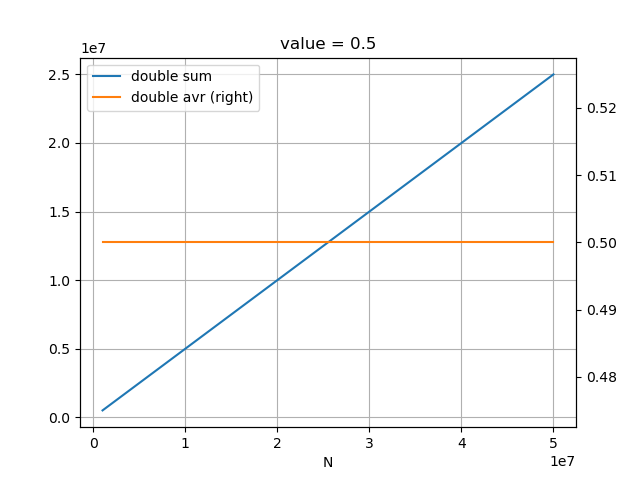
2.勝率の型をfloatからdoubleに変更
勝率の型をfloatからdoubleにすることで、UCBの勝率項の誤差が小さくなる。
測定結果
# PLAYER : RATING ERROR POINTS PLAYED (%) CFS(%) W D L D(%)
1 dlshogi : 2.5 10.1 507.0 1000 51 68 484 46 470 5
2 win_double : -2.5 10.1 493.0 1000 49 --- 470 46 484 5
# PLAYER : RATING ERROR POINTS PLAYED (%) CFS(%) W D L D(%)
1 YaneuraOu NNUE 5.32 64AVX2 : 15.9 10.0 1067.5 2000 53 91 1037 61 902 3
2 dlshogi : 1.4 15.8 479.5 1000 48 89 464 31 505 3
3 win_double : -17.4 15.8 453.0 1000 45 --- 438 30 532 3
少し弱くなっている。
1手3秒だと、UCBの勝率項の誤差よりもnpsの低下の方が影響していそうである。
大会で長時間思考した場合は、誤差の影響の方ができるかもしれないので、1手3秒よりも長時間で確認する必要がある(確認予定)。
少なくとも定跡作成時は、doubleにした方がよいので、型をtypdedefで変更可能とする予定である。
3.UCBの定数をループの外で計算
今までループの中で平方根を含む定数を計算していたため、ループの外で計算するようにした。
測定結果
# PLAYER : RATING ERROR POINTS PLAYED (%) CFS(%) W D L D(%)
1 ucb_const : 7.1 29.9 64.5 124 52 68 59 11 54 9
2 dlshogi : -7.1 29.9 59.5 124 48 --- 54 11 59 9
# PLAYER : RATING ERROR POINTS PLAYED (%) CFS(%) W D L D(%)
1 YaneuraOu NNUE 5.32 64AVX2 : 6.6 33.9 90.5 176 51 59 87 7 82 4
2 ucb_const : -1.5 54.3 42.0 86 49 53 41 2 43 2
3 dlshogi : -5.1 55.5 43.5 90 48 --- 41 5 44 6
対局数が少ないので、この結果で強くなったとは言えないが、この変更で弱くなることはないので採用した(masterに反映済み)。
4.atomicのメモリオーダーを指定
atomic変数にメモリオーダーを指定しないと、デフォルトでmemory_order_seq_cst(複数スレッドで変更を同期する)になる。
2変数以上の変更順序を保証する必要がある場合は、memory_order_seq_cstにする必要があるが、1変数であれば一番緩い設定のmemory_order_relaxedにできる。
Leela Chess ZeroやKataGoなどでもmemory_order_relaxedにしている。
測定結果
# PLAYER : RATING ERROR POINTS PLAYED (%) CFS(%) W D L D(%)
1 dlshogi : 3.7 11.4 396.5 777 51 74 359 75 343 10
2 memory_order : -3.7 11.4 380.5 777 49 --- 343 75 359 10
# PLAYER : RATING ERROR POINTS PLAYED (%) CFS(%) W D L D(%)
1 YaneuraOu NNUE 5.32 64AVX2 : 3.0 13.6 558.0 1102 51 52 544 28 530 3
2 memory_order : 2.4 22.1 278.5 558 50 64 271 15 272 3
3 dlshogi : -5.4 22.1 265.5 544 49 --- 259 13 272 2
自己対局ではなぜかむしろ弱くなっているが、誤差の範囲と言えそうだ。
x64のCPUであれば、atomicのload()は、memory_order_seq_cstでもmemory_order_relaxedでも同じ命令で、更新だけ異なるようである。
更新よりも参照回数が圧倒的に多いので影響がないと言えそうだ。
この変更は採用しなくても良さそうである。
5.詰み探索をtemplateで再帰処理する
今まで終端ノードでの詰み探索において、深さを引数に与えて、深さをデクリメントしながら再帰処理していた。
深さをC++のtemplate引数にすることで、再帰呼び出しをコンパイル時に行うようにした。
深さ3は3手詰め専用ルーチンを実装しているので、深さ3をtemplateで特殊化することで、template引数で再帰処理できるようにした。
測定結果
# PLAYER : RATING ERROR POINTS PLAYED (%) CFS(%) W D L D(%)
1 mate_depth_template : 9.4 29.8 69.5 132 53 73 64 11 57 8
2 dlshogi : -9.4 29.8 62.5 132 47 --- 57 11 64 8
# PLAYER : RATING ERROR POINTS PLAYED (%) CFS(%) W D L D(%)
1 mate_depth_template : 5.1 54.3 47.0 92 51 58 46 2 44 2
2 YaneuraOu NNUE 5.32 64AVX2 : -2.5 32.5 92.0 186 49 50 90 4 92 2
3 dlshogi : -2.5 54.2 47.0 94 50 --- 46 2 46 2
まだ測定中で対局数が少ないので有意とは言えないが、強くなっていそうである。
dlshogiでは、終端ノードでの詰み探索が終盤の王手の多い局面でのボトルネックになっているので、この部分は可能な限り高速化したい。
測定を続けて少なくとも弱くなっていなければ採用する予定である。
6.1手詰めルーチンをやねうら王から移植
dlshogiは局面管理にAperyのソースコードを流用していて、1手詰めルーチンもAperyのコードをそのまま利用している。
Aperyの1手詰めルーチンは、近接王手のみチェックしているため、飛車や角の離し王手や、開き王手で詰みになる場合はチェックしていない。
一方、やねうら王の1手詰めルーチンでは、離し王手でも相手玉の24近傍ではチェックしており、開き王手も両王手になる場合はチェックしている(ただし、やねうら王ではレーティングが向上していないということでコメントアウトされた)。
この処理をdlshogiにも移植を行った。
測定結果
# PLAYER : RATING ERROR POINTS PLAYED (%) CFS(%) W D L D(%)
1 mate1ply : 10.4 19.1 171.5 325 53 86 161 21 143 6
2 dlshogi : -10.4 19.1 153.5 325 47 --- 143 21 161 6
# PLAYER : RATING ERROR POINTS PLAYED (%) CFS(%) W D L D(%)
1 dlshogi : 13.2 32.1 126.5 240 53 81 123 7 110 3
2 YaneuraOu NNUE 5.32 64AVX2 : -5.8 20.2 230.5 473 49 53 221 19 233 4
3 mate1ply : -7.3 32.9 116.0 233 50 --- 110 12 111 5
まだ測定中だが、自己対局では強くなって、水匠2相手では弱くなっていそうという傾向になっている。
水匠2との対局は誤差が大きくでるので、500局以上測定できてから判断した方が良さそうだ。
MCTSの探索では速度重視で、Aperyの1手詰めルーチンで、ルートノードでのdf-pnではやねうら王の1手詰めルーチンという使い分けが良いかもしれない。
あと、現状詰み探索では速度重視で不成を生成していないが、ルートノードでのdf-pnは時間に余裕があるので不成も生成した方が良さそうだと気付いた(試す予定)。
7.候補手が1手のみの場合すぐに展開する
ノードの候補手が1手のみの場合、そのノードを評価しないですぐに展開して1手深く探索するようにした。
測定結果
# PLAYER : RATING ERROR POINTS PLAYED (%) CFS(%) W D L D(%)
1 onemove : 6.3 10.2 517.5 1000 52 89 480 75 445 8
2 dlshogi : -6.3 10.2 482.5 1000 48 --- 445 75 480 8
# PLAYER : RATING ERROR POINTS PLAYED (%) CFS(%) W D L D(%)
1 dlshogi : 10.1 17.0 429.0 826 52 88 418 22 386 3
2 YaneuraOu NNUE 5.32 64AVX2 : -3.6 11.1 820.0 1665 49 60 794 52 819 3
3 onemove : -6.5 17.0 416.0 839 50 --- 401 30 408 4
自己対局では強くなって、水匠2相手では弱くなるという判断に迷う結果になった。
不採用としておく。
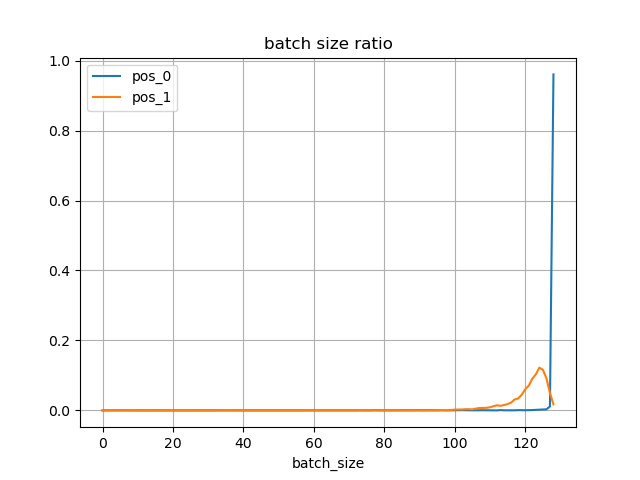
8.投機的な探索
マルチスレッドで探索ノードの衝突が起きた場合に、Virtual lossを一時的に上げて再探索し、新しいノードに達したら仮展開し、事前評価しておくようにする(バックアップは行わない)。
これにより、ノードの衝突が多いとNPSが低下するのを防ぐことができる。
実装してみたのだが、floodagateからサンプリングした100局面でNPSを測定した結果では、NPSは向上しなかった(少し低下した)。
平均NPS:242671.18 → 240905.84
V100×8でGPUあたり3スレッドで探索すると、通常でも十分にVirtual lossが加算されているので、さらに加算して探索したノードをキャッシュしてもほとんどキャッシュヒットしていない状況だと思われる。
バッチサイズを上げてNPSを向上するのは一筋縄ではいかなそうである。
引き続き課題として取り組む予定である。
まとめ
探索部の改良で行ったことを忘れないうちにまとめた。
上記のうち、いくつかはレーティング向上につながりそうである。
本日開催の電竜戦TSECでは、いくつかは取り込んだ上で参加するつもりである。