dlshogiでは、複数GPUを使用して並列化した場合に、ノードの衝突が発生しやすくなりNPSが1/3近くになる場合がある。
例として、電竜戦でA100×8使用した時、以下の局面でNPSが初期局面に対して1/3近くなっていた。
| 局面 | NPS |
|---|---|
| 初期局面 | 342985 |
| position startpos moves 7g7f 8c8d 2g2f 8d8e 8h7g 3c3d 7i8h 2b7g+ 8h7g 3a4b 2f2e 4b3c 6i7h 4a3b 3i3h 7a6b 3g3f 6c6d 5i6h 1c1d 3h3g 6b6c 6h7i 6c5d 3g4f 4c4d 3f3e 4d4e 3e3d 3c3d 4f3g 3b3c 2h3h 3d3e 4i4h 5a4a 2e2d 2c2d 3g3f 3e3f 3h3f P*3d P*2c S*3e 3f5f B*4d | 153259 |
原因
MCTSで並列化を行う場合に、バーチャルロスという仕組みで、探索するノードをばらけさせることが行われている。
並列度が高くなると、バーチャルロスを使っても、同じ終端ノードに到達することが多くなる。
終端ノードを展開するには、ポリシーネットワークの計算を待つ必要があり、同じ終端ノードに到達した場合は、それ以上探索できないため探索(プレイアウト)を破棄している。
dlshogiでは、バッチサイズ分の探索を行ってから、GPUでバッチでまとめてポリシーネットワーク(とバリューネットワーク)の計算するということを行っているため、破棄した探索があると、バッチサイズが小さくなり、GPUが十分に活用できなくなる。
上記の2局面について、V100×8を使用して探索した場合の、バッチサイズの割合は以下の通りとなった。
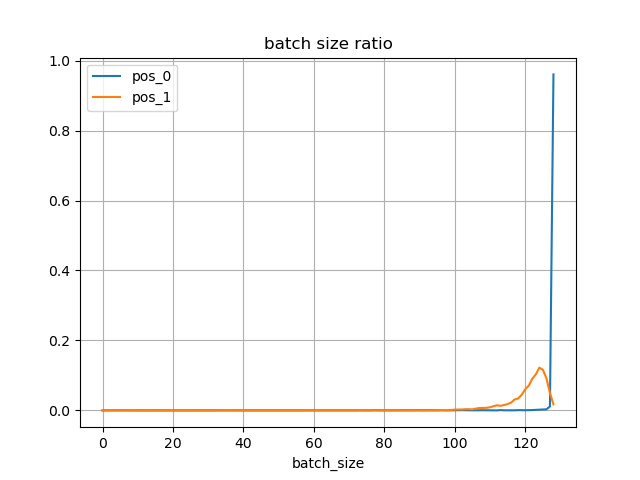
初期局面(pos_0)では、ほとんどがバッチサイズ128(最大)で、ノードの衝突がほとんど起きていない。
一方、NPSが落ちる局面(pos_1)では、バッチサイズが100~128の間に分布している。
ログスケールで見ると、50以下にも分布していることが分かる。

小さいバッチサイズで計算しても、大きいバッチサイズで計算しても、同じだけ時間を消費するため、小さいバッチサイズによるNPSへの影響は大きい。
対策
GPUを有効に活用するには、バッチサイズを大きくする必要がある。
ノードが衝突した場合は、予測が外れても良いので、将来展開されるノードをあらかじめ計算しておくことで、GPUのバッチサイズを大きくすることができる。
しかし、予測の精度が低すぎると、無駄になるため、ある程度の予測精度が欲しい。
対策案
- 展開済みのゲーム木から次に展開されそうな兄弟ノードを仮展開する
- 衝突した終端ノードで、次に展開される可能性が高い手を予測して、仮展開する
- 一時的にバーチャルロスを上げて、通常の探索を行い終端ノードを仮展開する
いずれの案でも、ノードを仮展開した後に不正確なノードがバックアップされると精度に影響がでるため、バックアップは行わない。
案1は、Leela Chess Zeroで実装されている方法である。
lc0/search.cc at 99fecc9dbd701c78a057aff77734213006f94014 · LeelaChessZero/lc0 · GitHub
案2は、なんらかの方法で予測が必要になる。CPUのみで高速に計算できるポリシーネットワークのようなものが必要になる。
案3は、ちょうどこのブログを書いていた時に、Discordでやねうらお氏からdlshogiの探索部についてダメだし?されていた時に頂いた案である(感謝!)。
とりあえず、Leela Chess Zeroの実装を参考に、案1を試してみるつもりである。
案2は、そこそこの精度のポリシーネットワークはそれなりに計算が重くなりそうである。軽量なポリシーネットワークの学習には興味あるので別途試してみるかもしれない。
案3は、案1より良くなる可能性もあるので比較してみたい。
まとめ
現状のdlshogiの並列化の課題について整理した。
並列化が改善されれば、探索部のみでもdlshogiの棋力はまだ伸びる見込みである。
(やる気が起きて)実装ができたら、また記事にする予定である。