前回、Value Networkの出力をtanhにした場合とsigmoidにした場合で比較を行ったが、マルチタスク学習を行っているため、はっきりした結果がわからなかった。
今回は、Value Networkのみの学習で比較を行った。
以下の2パターンで比較した。
| 出力関数 | 損失関数 | |
| 1 | tanh | 平均二乗誤差(MSE) |
| 2 | sigmoid | 交差エントロピー |
tanhとsigmoidの比較
測定条件
- 5ブロックのWide ResNet
- 訓練データ:7000万局面
- テストデータ:100万局面
- 1000万局面ごとに評価
- 学習率:0.001
- 最適化:SGD
- ミニバッチサイズ:64
average train loss

test loss

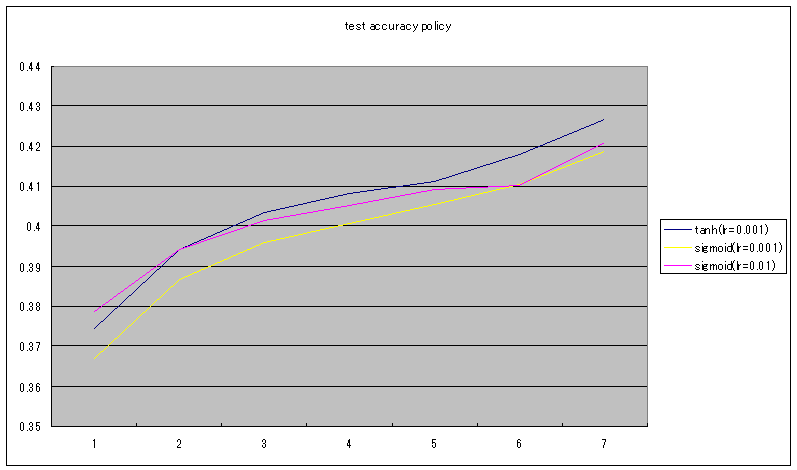
test accuracy

考察
train lossはスケールが違うため比較できない。どちらも減少している。
test lossはtanhは1000万局面でほぼ減少が止まっている。
sigmoidはわずかに減少している。
test accuracyは、tanhの方が一致率が高い。
以上の結果から、tanhの方が学習効率が高いと言えそうだ。
前回と今回の実験結果からtanhの方が良さそうなので、Value Networkの出力はtanhに変更することにする。
なお、1000局面でtest lossがほぼ下げ止まっているのは、elmo_for_learnでの局面生成時に初期局面(1000万局面くらい)から数手のランダムムーブを行っているとは言え、似たような局面が大量に生成されているためと思われる。
AlphaGoでもValue Networkの学習には1ゲームから1局面しか使っていないので、Value Networkの汎化性能を上げるには、局面のバリエーションがもっと必要と思われる。
AlphaGo Zeroでは、自己対局のみで学習しているので、局面が偏りそうだが実際に強くなっているので不思議な気がしている。AlphaGo ZeroでL2正則化を行っているのは、それが理由かもしれない。
将棋でAlphaGo Zeroと同じように自己対局のみで学習した場合にもうまくいくのかはやってみないとわからない。