将棋AIでは、評価関数をsigmoid関数で[0,1]の範囲で勝率にすることが行われている。
elmoの損失関数には、勝率の交差エントロピーと、浅い探索と深い探索の評価値から求めた勝率の交差エントロピーの和が使われている。
一方、AlphaGoでは報酬に[-1,1]が使用されており、ValueNetworkの出力にはtanhが使われている。
損失関数には、平均二乗誤差(MSE)が使用されている。
tanhを使用している理由は論文では特に説明されていないが、tanhの方が強い勾配が得られるそうだ。
machine learning - tanh activation function vs sigmoid activation function - Cross Validated
そこで、ValueNetworkの出力をtanhにして損失関数をMSEした場合と、出力をsigomidにして損失関数を交差エントロピーとした場合で比較してみた。
tanhの場合、ブートストラップ項(ValueNetworkの出力と深い探索の評価値の差)の損失関数もMSEとした。
tanhとsigmoidの比較
測定条件
average train loss

※policyとvalueの損失の合計
test loss

※policyとvalueの損失の合計
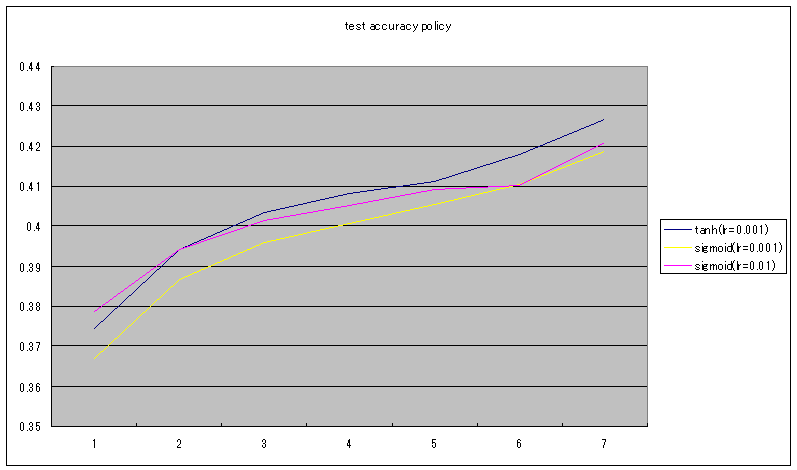
test accuracy policy
test accuracy value

考察
tanhの場合、学習率が0.01の場合、発散して学習できなかった。
学習率を0.001として測定した。
sigmoidも併せて学習率0.01の他に0.001でも測定した。
train loss、test lossはtanhの方が、sigmoidの場合より大きくなっているが、値の範囲が[-1,1]になったことで、損失関数のスケールが2倍になっていることが影響している。
policyのtest accuracyは、tanhの方がsigmoidの場合より大きくなっている。
valueのtest accuracyは、tanhの方がsigmoidの場合より小さくなっている。
tanhの場合、policyの損失関数は交差エントロピーで、valueの損失関数がMSEなので、policyとvalueの損失の比率が、sigmoidのときと変わったことが影響していると思われる。
どちらが良いともはっきりと言えない結果だが、同じ学習率(0.001)では、valueのtest accuracyがほぼ同じなのに対して、policyのtest accuracyはtanhの方が良くなっている。