Science誌に掲載された論文は、新しい対局条件での結果と棋譜の公開がメインで技術的な内容は、昨年のarXivで公開された論文とほとんど差分はありませんでした。
DeepMindのページのリンクからダウンロードできるOpen Access versionのMethodsでは、技術的な内容が追加されており、興味深い内容も記載されていました。
Prior Work on Computer Chess and Shogi
TD Gammonwasについて追加されています。
Domain Knowledge
引き分けの条件がチェスと将棋では512手、囲碁では722手であることが追加されています。
定跡と終盤データベースを使用していないことが追加されています。
Search
MCTSのアルゴリズムの説明が追加されています。
以前のAlphaGoからPUCTの定数が変更されており、親ノードの訪問回数応じた関数になっていました。
以前
今回
C(s)は探索の割合(exploration rate)で、探索の時間とともにゆっくり増加し、探索が高速な場合は、本質的には一定であると説明されています。
定数の値は、公開された疑似コードをみれば分かります。(Additional FilesのData S1に含まれるpseudocode.py)
# UCB formula self.pb_c_base = 19652 self.pb_c_init = 1.25
と定義されています。
グラフにすると以下のようになります。
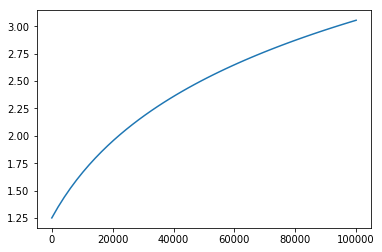
訪問回数が少ない内は探索結果を重視して、訪問回数が増えるとボーナス項の重みが大きくなり、未知の手が選択されやすくなると解釈できます。
Representation
ポリシーの予測した手について、合法でない手は確率を0にして、残りの合法手で再正規化するという説明が追加されています。
Architecture
ネットワーク構成の説明が追加されています。
- AlphaGo Zeroでは、ポリシーの出力に全結合層が使われていましたが、チェスと将棋では、畳み込み層であるという説明が追加(ポリシーの出力層の畳み込みのカーネルサイズについては記載されていません。)
チェスと将棋でポリシーの出力が畳み込み層になっていることから、AlphaGo Zeroでポリシーの出力が全結合層になっていた理由は、パスを表現するためであったと解釈できます。(個人的に知りたかった内容でした。)
バリューの出力層は、1フィルター、カーネルサイズ1×1の畳み込み層の後に、256ユニットの全結合層と1ユニットの全結合層で、tanhで出力しています。
チェスと将棋でも、畳み込み層は、1フィルターになっていました。
駒の種類が多いため、フィルタ数は多くしていると予測していましたが、そうではなかったようです。
バリューに関してはフィルターを1つにして、重みを共有した方がよいのかもしれません。
Configuration
学習率について詳細が追加されています。
学習率を0.2から0.02、0.002、0.0002に落とす条件が、チェスや将棋の場合は100、300、500,000ステップ後で、囲碁の場合は0、300、500,000ステップ後という条件が追記されています。
Opponents
- 対局相手のソフトの条件の記載が追加
定跡の仕様有無について一部で疑問が上がっていましたが、将棋は、やねうら王の標準定跡を使用していることが記載されています。
ハードウェアなどの詳細な条件が記載されていましたが割愛します。
Match conditions
対局条件について内容が追加されています。
初期局面から対局を行い、将棋の場合は2017年WCSCと同じ持ち時間10分、1手10秒加算の条件です。
AlphaZeroの時間制御は、単純に残り時間の1/20のようです。
ポンダーは、思考時間の評価を行うため、双方未使用の設定です。
投了の条件は、elmoは-4500が10回連続の場合、AlphaZeroはバリューが-0.9になった場合です。
1,000試合で勝率を評価しています。
Elo ratings
Eloレーティングの測定方法について内容が追加されています。
1手1秒の対局結果から評価したことが書かれています。
感想
ポリシーの出力層の構成が知りたかったことの一つだったので、有益な情報が得られたと思います。
PUCTの定数が訪問回数による関数に代わっていたことは、dlshogiでもどれくらい効果があるか試そうと思います。
疑似コードがPythonで実装されていたので、AlphaZeroもPythonで実装されているのか気になりました。
まだ全部読めていませんが、疑似コードを読むと自己対局から訓練の流れや、データの格納方法とかが推測できて楽しめます。
2018/12/9 追記
疑似コードを見ると、学習のハイパーパラメータがわかります。
自己対局して学習に使う局面数は、700,000ステップ(1ステップは4,096局面)と記載されていましたが、過去何局からサンプリングしているかは記載されていませんでした。(AlphaGo Zeroの論文には、most recent 500,000 gamesと記載されていました。)
疑似コードには、
### Training self.training_steps = int(700e3) self.checkpoint_interval = int(1e3) self.window_size = int(1e6) self.batch_size = 4096
と定義されており、ReplayBuffer.save_gameで、保存するゲームの数の上限がwindow_sizeになっていることから、直近1,000,000局からサンプリングしていることがわかります。