以前にdlshogiで方策の分布を学習できるようにしたが、方策の分布を学習したモデルで対局すると、指し手のみを学習したモデルよりも弱くなるという問題が起きている。
温度パラメータの調整である程度強くできたが、指し手のみを学習したモデルには及んでいない。
分布を学習することで、探索する手が広がるため、探索の深さが浅くなることが原因と考えている。
この特性は、強化学習を行う際には、新しい手を探索しやすくなるため有効に働く。
モデルの方策と価値のfloodgateの棋譜に対する精度も高くなることが分かっている。
世界コンピュータ選手権向けのモデルでは、方策の分布を学習して強化学習したモデルで生成した指し手を、別のモデルで学習するという手法をとった。
温度パラメータで調整
指し手のみを学習する際、方策を記録したhcpe3フォーマットから、指し手のみを記録したhcpeフォーマットに変換を行っていたが、これを温度パラメータで調整できるようにした。
学習する方策 を、ルートの子ノードaの訪問回数をN(a)、温度
を、ルートの子ノードaの訪問回数をN(a)、温度 として、
として、

として、学習する。
温度が0の場合は、指し手のみを学習する、温度が1の場合は、方策の分布を学習する。
温度が1より低い場合は、より訪問回数が多い手の確率が高くなり、温度が1より大きい場合はより確率が均一になる。
温度パラメータを変えて学習
温度パラメータを変えて学習した際の、テスト損失、テストエントロピーを比較した。
学習データにはdlshogiの強化学習で生成した4千万局面を使用し、既存モデルに追加学習した。
8回測定を行い平均をとった。
テストデータに、floodgateのレート3500以上の対局の棋譜からサンプリングした856,923局面を使用した。
| 温度 |
テスト方策損失 |
テスト価値損失 |
テストエントロピー |
| 0 |
1.817141809 |
0.52847061 |
1.350876433 |
| 0.3 |
1.770466749 |
0.527390403 |
1.354992663 |
| 0.5 |
1.739721565 |
0.52895042 |
1.393257098 |
| 0.8 |
1.704725165 |
0.523376935 |
1.489995551 |
| 0.9 |
1.690805215 |
0.523304745 |
1.555975463 |
| 1 |
1.681393201 |
0.522688101 |
1.592738526 |
| 1.1 |
1.680972238 |
0.523270845 |
1.639763045 |
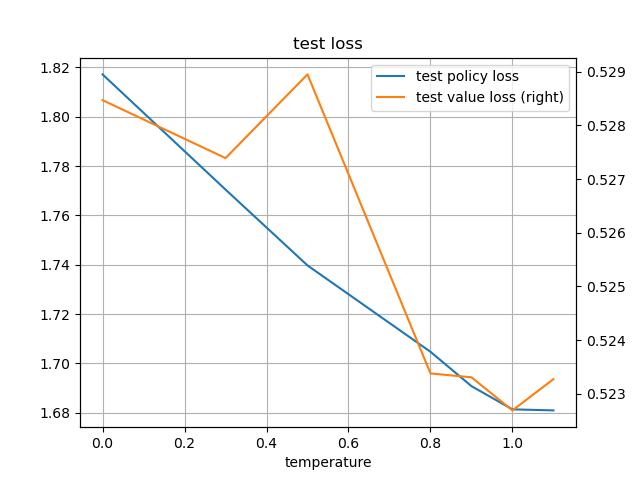
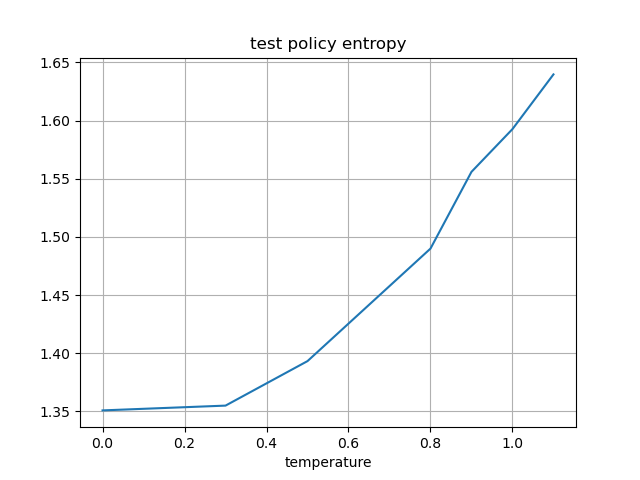
考察
温度が1の場合に価値の損失が一番低くなる。
また、温度が上がるほどエントロピーが上昇する(確率が均一に近づく)。
上で述べた性質が実験からも確認できた。
強さの比較
温度1と温度0.9で学習したモデルを使用して強さを比較した。
探索パラメータは、温度1で学習したモデル用に調整している。
持ち時間1分、1秒加算
# PLAYER : RATING ERROR POINTS PLAYED (%) CFS(%) W D L D(%)
1 gct_075_opt20_tmp09 : 6.6 13.0 592.0 1152 51 65 527 130 495 11
2 gct_075_opt20_tmp1 : 2.0 12.9 582.5 1155 50 83 519 127 509 11
3 susho3kai18th : -8.6 12.7 554.5 1151 48 --- 501 107 543 9
※gct_075_opt20_tmp09:温度0.9で学習したモデル、gct_075_opt20_tmp1:温度1で学習したモデル
有意差なしという結果になった。
ただし、モデルに合わせて探索パラメータも調整が必要になるので、差が出なかった可能性がある。
まとめ
方策を学習するか、指し手のみを学習するかを温度パラメータで調整できるようにした。
これによって、hcpe3フォーマットからhcpeへの変換が不要になる。
train_hcpe3で、指し手のみの学習もできるようになった。
温度パラメータによって、精度、エントロピーに違いがでることが確認できた。
温度が1の場合は精度が高く、エントロピーが高くなる。温度が0に近づくにつれ精度とエントロピーが下がる。
エントロピーが下がると、探索の幅より深さを優先することになるので、対局では有利に働く場合がある(持ち時間にも依存すると思われる)。
