Androidアプリの音声スペクトルモニター(Audio Spectrum Monitor)をバージョンアップしました。
要望のあったピークホールドの機能を追加しました。
ドラムのチューニングに使いたいという方がいて、瞬間のピッチを保持したいという要望をもらっています。
実装は難しくないですが、UIをどうするかが悩みどころです。
チューニング用途だと音階と周波数Hz表示は必須と思われますが、リアルタイムの表示と2つ表示するとごちゃごちゃしそうで、エレガントなUIをひらめき待ちです。
Androidアプリの音声スペクトルモニター(Audio Spectrum Monitor)をバージョンアップしました。
要望のあったピークホールドの機能を追加しました。
ドラムのチューニングに使いたいという方がいて、瞬間のピッチを保持したいという要望をもらっています。
実装は難しくないですが、UIをどうするかが悩みどころです。
チューニング用途だと音階と周波数Hz表示は必須と思われますが、リアルタイムの表示と2つ表示するとごちゃごちゃしそうで、エレガントなUIをひらめき待ちです。
Androidアプリの音声スペクトルモニター(Audio Spectrum Monitor)をバージョンアップしました。
しばらく将棋AIばかり作っていたので、アプリの開発が止まっていましたm(_ _)m
もらっていた要望のうち、とりあえずGoogleドライブに転送する機能を追加しました。
アプリで保存したファイルはどこに保存されるのか?という質問をよく受けていたのですが、Androidのアプリで保存したファイルはセキュアな領域に保存されるため、他のアプリから直接参照することができません。
代替策として、インテントを使ってオーディオファイルに対応したアプリに転送できるようにしました。
Googleドライブに転送することで、ファイルとして取り出すことができます。
あと、ピークホールドを追加してほしいという要望ももらっていますが、近いうちに対応する予定です。
前回の日記で、ブートストラップについて少し書いたが、1000万局面では効果がわからなかったので、局面を増やして再度検証した。
前回も書いたが、本来の報酬(勝敗)とは別の推定量(探索結果の評価値)を用いてパラメータを更新する手法をブートストラップという。
elmo_for_learnで生成したデータには、局面の探索結果の評価値が含まれているので、バリューネットワークの値をその評価値に近づけるように学習することで、学習の効率を上げることができると思われる。
経験的にブートストラップ手法は、非ブートストラップ手法より性能が良いことが知られている。
elmoと同様に、ブートストラップ項の損失には、2確率変数の交差エントロピーを使用する。
バリューネットワークの値を、探索結果の評価値をシグモイド関数で勝率に変換した値を
とした場合、交差エントロピーは以下の式で表される。
交差エントロピーの偏微分は、
となるが、Chainerで実装する場合、backwardの処理をGPUで計算できるように、cudaの処理を記述する必要がある。
技量不足でその部分を実装できなかったため、交差エントロピーを以下のように計算して、微分は計算グラフの処理に任せることにした。
def cross_entropy(p, q): return F.mean(-p * F.log(q) - (1 - p) * F.log(1 - q))
このブートストラップ項に係数を掛けて、元の損失関数に加える。
損失関数は以下の通りになる。
loss1 = F.mean(F.softmax_cross_entropy(y1, t1, reduce='no') * z) loss2 = F.sigmoid_cross_entropy(y2, t2) loss3 = cross_entropy(F.sigmoid(y2), value) loss = loss1 + loss2 + args.val_lambda * loss3
loss1は指し手予測(policy network)の損失、loss2は勝率予測(value policy)の損失、loss3がブートストラップ項である。
ブートストラップなしで2億局面学習したモデルから、ブートストラップなし/ありで、8000万局面を学習して精度を比較した。
| train loss1 | train loss2 | train loss3 | test acc.(policy) | test acc.(value) | |
| ブートストラップ項なし | 0.8883 | 0.4638 | 0.4439 | 0.7651 | |
| ブートストラップ項あり | 0.8853 | 0.4741 | 0.4427 | 0.4444 | 0.7658 |
train loss2(value networkの損失)は、ブートストラップ項のなしの方が減少しているが、test accuracyはブートストラップ項ありの方がわずかに良い。
train loss3はブートストラップ項ありの場合のみ測定しているが、初期から減少を続けており、value networkの予測が評価値に近づいている。
ブートストラップ項ありで学習したモデルで、GPSfishと対局させた。

GPSfishに勝つことができた。
評価値はGPSfishとほぼ同じ傾向だが、GPSfishより早く評価値が付いている。
ブートストラップ項なしで学習したモデルでは以前と同様に、評価値がGPSfishより遅れて不利を判断しており、勝つことができなかった。
ブートストラップ項を追加することで、バリューネットワークの学習効率が上がることが確かめられた。
これで、ディープラーニングのみでも(GPSfishよりも)強いソフトが作れることが確認できた。
この方法で、さらに学習を進める予定。
前回の日記で、利きを入力特徴に加えることで精度が上がることを確認したので、利きを追加したモデルで、初期値から学習をやり直した。
学習データには、elmo_for_learnで深さ8で生成した、1億5千万局面を使用した。
以前に生成したときは、引き分けの局面も出力していたが、引き分けの報酬を0(または1)として学習すると、精度に悪影響があるため、今回は引き分けは出力しないようにした。
ミニバッチサイズ32で、1000iterationごとのtrain loss、test accuracyは以下の通りとなった。
policy networkとvalue networkをマルチタスク学習しているので、test accuracyはそれぞれ求めている。
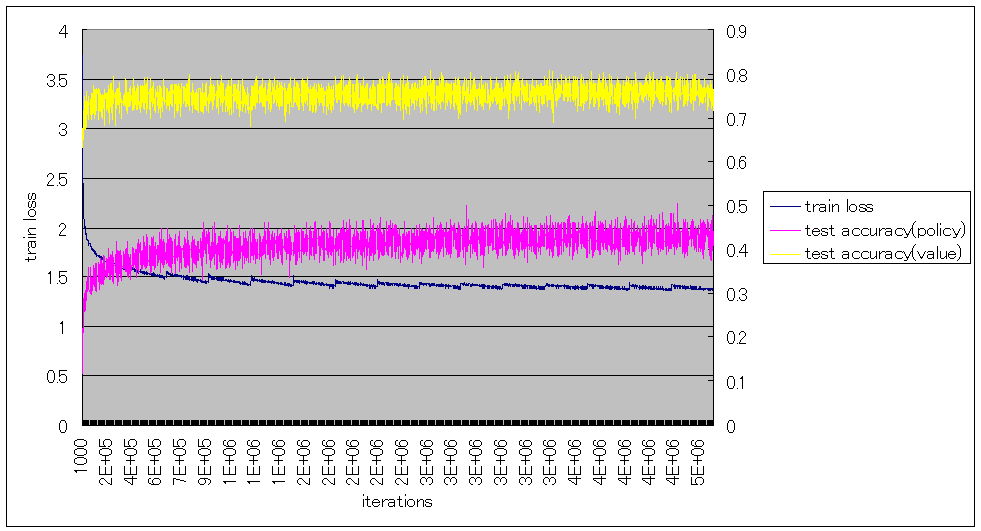
train lossが急に上がっている箇所は、棋譜を1000万局面単位で生成してその単位でソートしているため、局面に偏りが出ているためである。
1000万局面を1epochとした場合、epoch単位では以下の通りとなった。
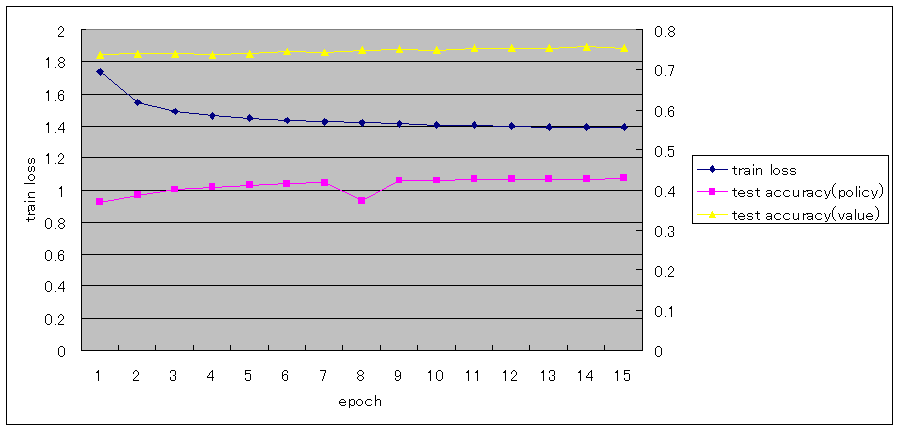
train lossは、まだ減少しているが、ほとんど進まなくなっている。
test accuracy(policy)もまだ増えているが、ほとんど進まなくなっている。
test accuracy(value)は、10epochあたりから0.75から変化していない。
GPSfishと対局すると、GPSfishが劣勢と判断している局面でも優勢と判断しており、かなり遅れてマイナスとなっている。
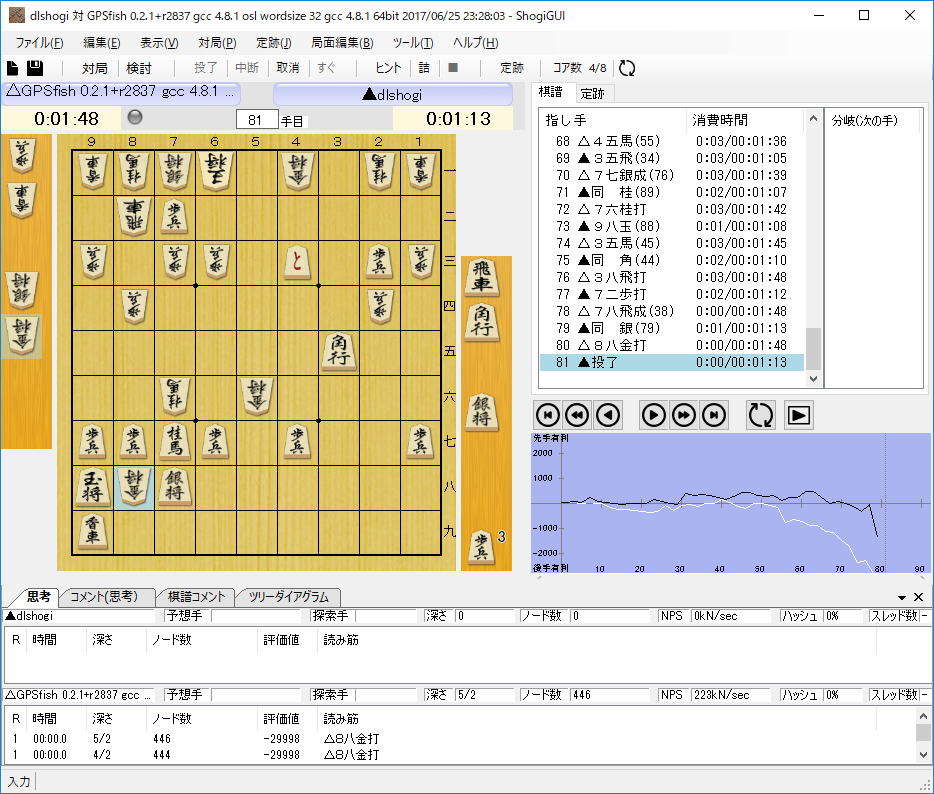
バリューネットワークが勝敗がはっきりするまで局面を正しく学習できていないようである。
バリューネットワークは、局面の勝率を学習するため、似た局面での勝ち、負けのデータが十分な量必要になる。
1億5千万局面では不十分と思われる。
勝率は確率的な事象であるため、バッチサイズが小さいと学習できない可能性があるため、バッチサイズを変えて学習してみた。
16epoch目をミニバッチサイズを変えて学習した場合の、train lossとtest accuracyは以下の通りとなった。
| ミニバッチサイズ | train loss1 | train loss2 | train loss | test acc.(policy) | test acc.(value) |
| b=32 | 0.9122 | 0.4522 | 1.3644 | 0.4301 | 0.7569 |
| b=64 | 0.9102 | 0.4592 | 1.3694 | 0.4362 | 0.7604 |
| b=128 | 0.8997 | 0.4672 | 1.3669 | 0.4377 | 0.7626 |
| b=256 | 0.8997 | 0.4683 | 1.3680 | 0.4386 | 0.7620 |
| b=512 | 0.8998 | 0.4684 | 1.3683 | 0.4380 | 0.7620 |
| b=1024 | 0.9049 | 0.4719 | 1.3769 | 0.4371 | 0.7609 |
loss1は指し手(policy network)の損失、loss2は勝率予測(value network)の損失を示す。
b=32がtrain lossが一番低くなっているが、test accuracyは一番悪くなった。
b=256がtest accuracy(policy)が最も高い。test accuracy(value)は、b=128が最も高いが、b=256,512もほぼ同じである。
よって、b=256を採用することにする。
学習時間もb=32では1000万局面で1:56:08だったが、b=256にすることで1:15:18と短くなる。
elmo_for_learnで生成したデータには、局面の探索結果の評価値が含まれている。
バリューネットワークの値をその評価値に近づけるように学習することで、学習の効率を上げることができないか試した。
このように別の推定量を用いてパラメータを更新する手法をブートストラップと呼び、elmoでも用いられている。
また、数手先の探索の評価値を用いるため、TD学習とも呼ばれる。
理論的には理由が明らかにされていないが、経験的にブートストラップ手法は、非ブートストラップ手法より性能が良いことが知られている。
| train loss1 | train loss2 | train loss3 | test acc.(policy) | test acc.(value) | |
| ブートストラップなし(b=128) | 0.9031 | 0.4620 | 0.5077 | 0.4377 | 0.7628 |
| ブートストラップあり(b=128) | 0.9007 | 0.4744 | 0.4466 | 0.4370 | 0.7621 |
train loss3はブートストラップ項の損失で、バリューネットワークの値と探索結果の評価値をシグモイド関数で勝率に変換した値との交差エントロピーを示す。
ブートストラップ項の損失には係数を掛けている。
train loss3は下がっているので、評価値に近づいているが、test accuracy(value)はほとんど変わっていない。
この測定だけでは、効果があるか不明である。
一旦採用しないで学習を進めることにする。
Windowsで安定して使用できるv1.24を使用していましたが、Chainer v2.0でパフォーマンスが向上するということなので、アップデートしました。
v1.24用のコードに一部修正が発生しましたが、軽微な修正で対応できました。
以前の日記を参照してください。
v1.24をアンインストールして、インストールし直す。
pip uninstall chainer pip install chainer --no-cache-dir
GPUを使用する場合は、cupyを追加でインストールする。
pip install cupy
git clone https://github.com/pfnet/chainer.git cd chainer python examples\mnist\train_mnist.py -g 0
成功すれば、以下のように表示される。
H:\src\chainer>python examples\mnist\train_mnist.py -g 0 GPU: 0 # unit: 1000 # Minibatch-size: 100 # epoch: 20 epoch main/loss validation/main/loss main/accuracy validation/main/accuracy elapsed_time 1 0.192455 0.0952584 0.942016 0.9691 41.9665 2 0.0766379 0.0824858 0.975816 0.9736 44.3679 3 0.0475103 0.0777052 0.984365 0.9759 46.7663 4 0.0350414 0.0709947 0.988666 0.9795 49.1532 5 0.0306068 0.0739683 0.990015 0.9812 51.5701 6 0.0223621 0.082753 0.992615 0.9787 53.9638 7 0.0204088 0.07966 0.993482 0.9805 56.4207 8 0.0193365 0.074065 0.993732 0.9814 58.8356 9 0.0145758 0.0646451 0.995515 0.985 61.2115 10 0.015124 0.087687 0.995498 0.981 63.6042 11 0.0152862 0.0875953 0.995016 0.9826 65.9779 12 0.0150241 0.0847389 0.995349 0.983 68.3442 13 0.00898874 0.0903441 0.997049 0.9807 70.6993 14 0.0138175 0.124715 0.995916 0.9764 73.0819 15 0.00765957 0.0941705 0.997549 0.9818 75.4683 16 0.0109906 0.116298 0.996966 0.9781 77.8691 17 0.0103545 0.0987549 0.996749 0.9824 80.2834 18 0.0108863 0.127021 0.997149 0.9787 82.7075 19 0.0088669 0.120687 0.997332 0.9792 85.0907 20 0.00868301 0.108154 0.997749 0.9821 87.4538
自分が記述したコードで、対応が必要な個所は以下の通りでした。
BatchNormalizationのtestオプションと、dropoutのtrainオプションを削除し、モデル実行時に
with chainer.using_config('train', False):
を使用する。
Variableのvolatileオプションを削除し、モデル実行時に
with chainer.no_backprop_mode():
を使用する。
v2.0にすることでパフォーマンスが向上するか確認した。
検証している将棋のWide Resnetのモデルの学習時間で比較した。
| time(mm:ss) | |
| v1.24 | 0:21:01 |
| v2.0 | 0:19:53 |
学習時間が5.39%向上した。
また、Windowsで問題なく実行できた。
モデルの精度を上げるために、入力特徴を追加して精度が上がるか検証しました。
AlphaGoでは盤面の情報に加えて呼吸点などの情報を入力特徴に加えることで、精度が向上している。
盤面の情報(4個の特徴)のみでは、test accuracyが47.6%だが、48個の特徴とすることで、55.4%となっている。
一方、私が作成した将棋用のWide Resnetのモデルでは、盤面+王手のみを入力特徴とした場合、1億3千万局面でtest accuracyが43.4%まで学習できたが、それ以上は精度が上がらなくなっている。
そこで、入力特徴を追加して精度が上がるか検証する。
追加する入力特徴は、ShogiNet(GAN将棋)のアピール文章を参考にした。
入力特徴を一つずつ追加して、精度を測定し効果があった場合、その特徴を採用して次の特徴を検証した。
elmo_for_learnで深さ8で生成した20万局面で初期値から学習を行い、テストデータ2万局面で比較を行う。
勝敗データを報酬の重みとして、バリューネットワークも同時に学習を行う。
成りゾーンを追加した場合、以下のようになった。
| train loss | test accuracy(policy) | test accuracy(value) | |
| 成りゾーンなし | 1.7554 | 0.2984 | 0.7947 |
| 成りゾーンあり | 1.7620 | 0.2954 | 0.7980 |
効果が見られなかったので、不採用とする。
成りゾーンの位置の情報はすでに表現できていたと思われる。
利き数とは、座標ごとにいくつの利きがあるかを表す。
8方向と桂馬を含めて最大10となるが、上限値を設ける。
上限値を1,2,3,4とした場合で比較した。
| 利き数上限 | train loss | test accuracy(policy) | test accuracy(value) |
| 利き数なし | 1.7554 | 0.2984 | 0.7947 |
| 1 | 1.7307 | 0.3024 | 0.7936 |
| 2 | 1.7022 | 0.3128 | 0.8160 |
| 3 | 1.6939 | 0.3143 | 0.8158 |
| 4 | 1.6833 | 0.3147 | 0.8005 |
利き数上限2にすると、test accuracy(policy)が1.44%、test accuracy(value)が2.13%上がった。
利き数上限3にすると、test accuracy(policy)はさらに上がり1.59%となり、test accuracy(value)はほぼ同じである。
利き数上限4にすると、test accuracy(policy)はさらに上がっているが、test accuracy(value)は下がっている。
利き数は守備が弱い箇所、強い箇所を測る指標になるので、囲碁における呼吸点のような意味を持つ。
policy、valueともに精度が上昇しており、効果的な特徴のようだ。
利き数上限3を採用することにする。
駒の種類ごとに、どのマスに利いているかを表す。
| train loss | test accuracy(policy) | test accuracy(value) | |
| 駒の利きなし | 1.6939 | 0.3143 | 0.8158 |
| 駒の利きあり | 1.6628 | 0.3222 | 0.7950 |
policyの精度は上がったが、valueは下がった。
policyはモンテカルロ木探索で補完できるので、valueを重視し不採用とする。
aperyのCheckInfoのdcBBとpinnedを使用する。
それぞれ、間の駒を動かした場合に王手になる駒と、動かすと王手にされる駒を表す。
| train loss | test accuracy(policy) | test accuracy(value) | |
| 王手情報なし | 1.6939 | 0.3143 | 0.8158 |
| 王手情報あり | 1.6869 | 0.3199 | 0.8029 |
policyはほぼ変わらず、valueが下がった。
不採用とする。
| train loss | test accuracy(policy) | test accuracy(value) | |
| 歩のある筋なし | 1.6939 | 0.3143 | 0.8158 |
| 歩のある筋あり | 1.6977 | 0.3143 | 0.8071 |
policyはほぼ変わらず、valueが下がった。
不採用とする。
明らかに効果があったのは、利きの数のみであった。
利き数(上限3)を採用することで、policyが1.59%、valueが2.11%向上した。
修正したモデルを使用して、一から学習し直す予定。
初期値と学習データの並びによって、value networkはぶれることがあるようなので、駒の利きと王手情報は採用してもよいかもしれない。
学習データを増やして追試を行う予定。
同じ条件で再度、駒の利きを追加して学習した。
| train loss | test accuracy(policy) | test accuracy(value) | |
| 駒の利きなし | 1.6939 | 0.3143 | 0.8158 |
| 駒の利きあり | 1.6576 | 0.3246 | 0.8095 |
policyの精度は1.03%上がって、valueはほぼ同じになった。
valueは毎回1~2%ぶれるので、採用することにする。
王手情報も駒の利きを採用した状態で再度学習した。
| train loss | test accuracy(policy) | test accuracy(value) | |
| 王手情報なし | 1.6576 | 0.3246 | 0.8095 |
| 王手情報あり | 1.6533 | 0.3256 | 0.8224 |
policyはほとんど変わっていない。
valueは増えているが誤差と思われる。
不採用とする。
駒の利きがない場合とある場合で、1000万局面を学習し、テストデータ10万局面で評価した結果、以下の通りとなった。
| train loss | test accuracy(policy) | test accuracy(value) | |
| 駒の利きなし | 1.4483 | 0.3655 | 0.8210 |
| 駒の利きあり | 1.4370 | 0.3723 | 0.8210 |
駒の利きはpolicyの精度に効果があることが確かめられた。