dlshogiは、世界コンピュータ将棋選手権 1次予選、8位でぎりぎり通過できました。
3敗したうち、2つはやねうら王ライブラリのソフトでかなり棋力差がある感じでしたが、8戦目のあやめとの対局は去年の2次予選では勝っていたソフトなので、60手であっさり負けてしまいくやしい負けでした。
事前に探索して作成した定跡に問題があるのかと思って、帰ってから調べましたが、定跡の手には問題なさそうでした。
1手ずつやねうら王で検証してみましたが、38手目の以下の局面での3八銀打が悪手だったようです。
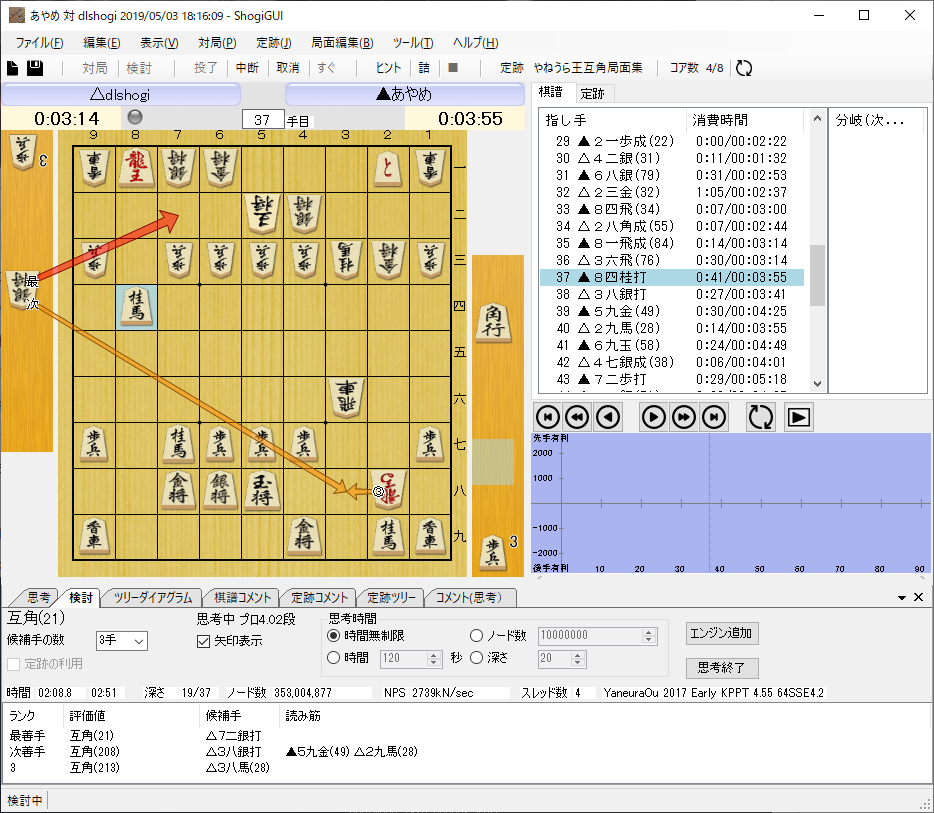
やねうら王の最善手は7二銀打で、評価値は互角ですが、3八銀打の後に評価値200程先手有利に傾いていました。
問題の局面で、方策ネットワークの指し手の確率が、
3八銀打 : 0.205184
7二銀打 : 0.000438275
となっており、7二銀打が完全に読みから外れており探索されていない状態となっていました。
policyの読み漏れは、以前は少しノイズを入れて対策していましたが、今回はノイズは入れていませんでした。
試しにノイズを入れて探索してみましたが、7二銀打の評価が良くなるわけではなく、根本的にはpolicyの精度を上げるしかなさそうです。
誤差の大きい局面の精度をどう上げるかが今後の課題となりそうです。
明日の2次予選通過は厳しそうですが、(今から何かできるわけではありませんが)できれば2勝したいところです。
2019/5/7 追記
valueの評価については、以下の通りとなっていました。
3八銀打 : 0.40625
7二銀打 : 0.01416
Apery(wcsc28)で検討すると、上記局面の最善手は、2七馬で評価値65の互角でした。
policy : 0.0615937
value : 0.379883(先手有利)
policyは比較的高いですが、valueはAperyの互角の評価とずれています。
Aperyは、7二銀打は、先手優勢1015点となっており、Aperyが正しいとすると、
7二銀打のpolicyとvalueの精度は正しいことになります。
なお、policyとvalueの上位5つは以下の通りとなっていました。
| |
policy |
value |
| 1 |
3八銀打(0.203322) |
2九馬(0.563965) |
| 2 |
2九馬(0.203322) |
3八銀打(0.40625) |
| 3 |
3八馬(0.089332) |
3八馬(0.399902) |
| 4 |
4五桂(0.0789503) |
2七馬(0.379883) |
| 5 |
2七馬(0.0615937) |
4五桂(0.316895) |












