ほぼ個人メモです。
画像認識のモデルで、畳み込みを使わずMLPのみ同等の精度が出せるというMLP Mixerの発展形であるgMLPを試してみた。
gMLP
チャネル方向と、空間方向に分けてMLPを適用する構成は、MLP Mixerと同じだが、Spatial Gating Unit (SGU)という仕組みを使うことで、空間的相互作用をとらえられるようになり、非正方形の畳み込みを学習することができるそうだ。
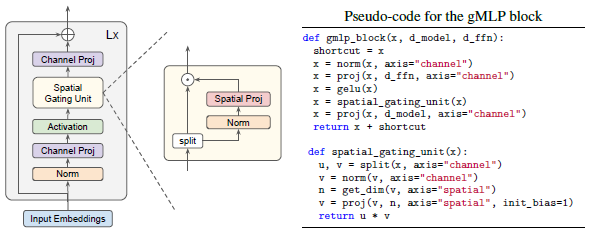
ただし、画像認識の精度は最高精度の畳み込みのモデルには及ばないようだ。
自然言語処理にも使えて、タスクによってはBERTと同等の精度になるようだ。
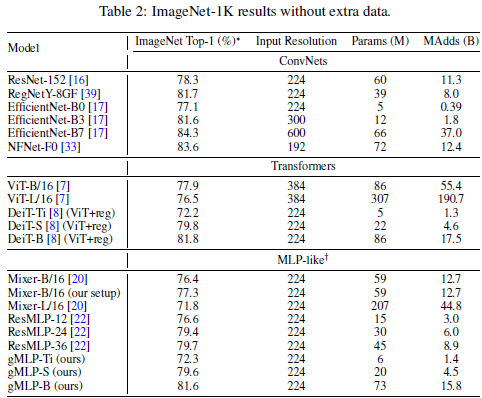
ResNet(ResNet-152)と比べると、gMLP-Sは少ないパラメータ数で同等以上の精度を達成している。
CIFAR-100で試す
CIFAR-100で、ResNetと比較してみた。
実装は、timmの実装を使用した。
timmは、ImageNet用のモデルになっているため、CIFAR-100で試すには一部修正が必要だった。
gMLP
mlp_mixer.pyに以下の定義を追加した。
@register_model
def gmlp_18_64_3_32(pretrained=False, **kwargs):
model_args = dict(
img_size=32, patch_size=3, num_blocks=18, embed_dim=64, mlp_ratio=6, block_layer=SpatialGatingBlock,
mlp_layer=GatedMlp, **kwargs)
model = _create_mixer('gmlp_18_64_3_32', pretrained=pretrained, **model_args)
return model学習のハイパーパラメータは論文の値を参考にした。
以下のコマンドで100epoch学習した。
python train.py cifar100/ --dataset torch/cifar100 --dataset-download --input-size 3 32 32 --num-classes 100 --model gmlp_18_64_3_32 --opt adamw --opt-eps 1e-6 --lr 1e-3 --warmup-lr 1e-6 --weight-decay 0.05 --clip-grad 1 -b 128 --epochs 100 --amp
学習結果は以下の通り。
(略) Train: 109 [ 0/390 ( 0%)] Loss: 1.343 (1.34) Time: 0.261s, 489.66/s (0.261s, 489.66/s) LR: 1.000e-06 Data: 0.166 (0.166) Train: 109 [ 50/390 ( 13%)] Loss: 1.628 (1.55) Time: 0.095s, 1346.62/s (0.098s, 1305.57/s) LR: 1.000e-06 Data: 0.004 (0.007) Train: 109 [ 100/390 ( 26%)] Loss: 1.741 (1.54) Time: 0.102s, 1251.79/s (0.097s, 1324.35/s) LR: 1.000e-06 Data: 0.004 (0.005) Train: 109 [ 150/390 ( 39%)] Loss: 1.396 (1.54) Time: 0.097s, 1318.39/s (0.096s, 1331.55/s) LR: 1.000e-06 Data: 0.003 (0.005) Train: 109 [ 200/390 ( 51%)] Loss: 1.686 (1.54) Time: 0.092s, 1396.70/s (0.096s, 1336.16/s) LR: 1.000e-06 Data: 0.003 (0.005) Train: 109 [ 250/390 ( 64%)] Loss: 1.568 (1.54) Time: 0.091s, 1408.70/s (0.095s, 1340.75/s) LR: 1.000e-06 Data: 0.004 (0.004) Train: 109 [ 300/390 ( 77%)] Loss: 1.497 (1.54) Time: 0.099s, 1298.39/s (0.095s, 1345.71/s) LR: 1.000e-06 Data: 0.004 (0.004) Train: 109 [ 350/390 ( 90%)] Loss: 1.527 (1.54) Time: 0.091s, 1410.79/s (0.095s, 1349.20/s) LR: 1.000e-06 Data: 0.004 (0.004) Train: 109 [ 389/390 (100%)] Loss: 1.280 (1.54) Time: 0.089s, 1432.73/s (0.095s, 1348.79/s) LR: 1.000e-06 Data: 0.000 (0.004) Test: [ 0/78] Time: 0.083 (0.083) Loss: 1.3799 (1.3799) Acc@1: 68.7500 (68.7500) Acc@5: 85.9375 (85.9375) Test: [ 50/78] Time: 0.019 (0.022) Loss: 1.4971 (1.5826) Acc@1: 64.8438 (62.2089) Acc@5: 89.0625 (84.5588) Test: [ 78/78] Time: 0.017 (0.022) Loss: 1.4111 (1.5565) Acc@1: 75.0000 (62.4500) Acc@5: 81.2500 (84.9400) *** Best metric: 62.64 (epoch 74)
SOTAのaccuracyは96.08なので、それに比べたら精度が低い。
CIFAR-100 Benchmark (Image Classification) | Papers With Code
ResNet18
gMLPは18ブロックとしたので、ResNetも18ブロックのモデルを使用した。
ResNetの実装もImageNet用になっているため、以下の箇所を修正した。
resnet.py
class ResNet(nn.Module):
(略)
def __init__(
(略)
# Stem
(略)
#self.conv1 = nn.Conv2d(in_chans, inplanes, kernel_size=7, stride=2, padding=3, bias=False)
self.conv1 = nn.Conv2d(in_chans, inplanes, kernel_size=3, stride=1, padding=1, bias=False)正則化などのハイパーパラメータはデフォルトのままとし、以下のコマンドで100epoch学習した。
python train.py cifar100/ --dataset torch/cifar100 --dataset-download --input-size 3 32 32 --num-classes 100 --model resnet18 --opt adam --lr 1e-3 --warmup-lr 1e-6 -b 128 --epochs 100 --amp
学習結果は以下の通り。
Train: 109 [ 0/390 ( 0%)] Loss: 1.708 (1.71) Time: 0.217s, 590.99/s (0.217s, 590.99/s) LR: 1.000e-06 Data: 0.175 (0.175) Train: 109 [ 50/390 ( 13%)] Loss: 1.447 (1.51) Time: 0.036s, 3560.15/s (0.051s, 2486.26/s) LR: 1.000e-06 Data: 0.004 (0.008) Train: 109 [ 100/390 ( 26%)] Loss: 1.480 (1.51) Time: 0.033s, 3929.15/s (0.049s, 2620.71/s) LR: 1.000e-06 Data: 0.004 (0.006) Train: 109 [ 150/390 ( 39%)] Loss: 1.588 (1.49) Time: 0.033s, 3897.49/s (0.047s, 2704.57/s) LR: 1.000e-06 Data: 0.004 (0.005) Train: 109 [ 200/390 ( 51%)] Loss: 1.453 (1.49) Time: 0.035s, 3654.12/s (0.045s, 2867.00/s) LR: 1.000e-06 Data: 0.003 (0.005) Train: 109 [ 250/390 ( 64%)] Loss: 1.550 (1.49) Time: 0.034s, 3718.97/s (0.043s, 2951.21/s) LR: 1.000e-06 Data: 0.004 (0.005) Train: 109 [ 300/390 ( 77%)] Loss: 1.513 (1.49) Time: 0.044s, 2910.11/s (0.043s, 2997.72/s) LR: 1.000e-06 Data: 0.004 (0.005) Train: 109 [ 350/390 ( 90%)] Loss: 1.556 (1.49) Time: 0.046s, 2767.55/s (0.042s, 3026.09/s) LR: 1.000e-06 Data: 0.004 (0.005) Train: 109 [ 389/390 (100%)] Loss: 1.493 (1.49) Time: 0.031s, 4186.29/s (0.042s, 3068.63/s) LR: 1.000e-06 Data: 0.000 (0.005) Test: [ 0/78] Time: 0.070 (0.070) Loss: 1.2080 (1.2080) Acc@1: 75.0000 (75.0000) Acc@5: 91.4062 (91.4062) Test: [ 50/78] Time: 0.010 (0.015) Loss: 1.3047 (1.3169) Acc@1: 68.7500 (67.1109) Acc@5: 89.0625 (88.5570) Test: [ 78/78] Time: 0.007 (0.015) Loss: 1.3691 (1.3144) Acc@1: 75.0000 (67.2800) Acc@5: 81.2500 (88.5800) *** Best metric: 67.62 (epoch 95)
gMLPより少し良い精度になった。
学習時間とパラメータ数
学習時間は、ResNetはgMLPの1/2くらいになっている。
パラメータ数は、gMLPの方が少ない。(torchsummaryの結果)
| gMLP(18ブロック) | 871,052 |
| ResNet18 | 11,220,132 |
パラメータ数が少ないにも関わらず学習時間がかかっているのは、ResNetは畳み込みにTensorCoreが使用できるためと思われる。
GPUには3090 RTXを使用して、学習にはAMPを使用している。