前回の日記で、SGDでSL policy networkを学習し、学習が成功していることが確かめられた。
学習アルゴリズムをSGDにしたのは、AlphaGoの論文で採用されていたからだ。
収束に非常に時間がかかるので、別の方法だともっと収束が早くならないか試してみた。
また、なぜSGDなんていう古典的な方法を使うのか疑問があったので確かめたかった。
学習アルゴリズムはMNISTサンプルで使われていたAdamにした。
前回と同様10万ミニバッチを実行して実験してみた結果が以下のグラフである。
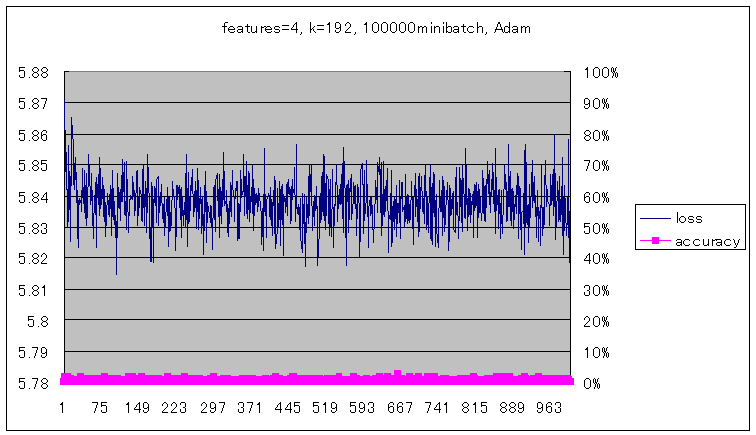
結果、収束が早くなるどころかまったく学習できなかった。
理由はちょっとわからない。
AlphaGoの論文でSGDが採用されているのも他のアルゴリズムより有効だからかもしれない。