ほぼ個人的なメモです。
電竜戦で、dlshogiで作成した定跡で序盤に先手の評価値が異常に高い局面が登録されていた。
例)7手目の評価値が238と高い

定跡作成時は、5000万ノード探索を行っており、探索ノード数が増えた場合に発生することが分かった。
当該局面の探索ノード数と評価値の変化

4000万局面あたりから評価値が単調に上昇している。
GCTのモデル
GCTのモデルで同一局面を探索した場合は、以下のようになった。

評価値は60くらいから徐々に下がっていき、5000万ノードでほぼ互角という評価になっている。
原因
dlshogiとGCTのPVのinfoは、それぞれ以下のようになっている。
dlshogiのPVのinfo
info nps 207030 time 241515 nodes 50000935 hashfull 1000 score cp 240 depth 33 pv 7i8h 4a3b 2f2e 2b7g+ 8h7g 3a2b 6i7h 2b3c 3i3h 7a7b 1g1f 7c7d 3g3f 8a7c 5i6h 6c6d 2i3g 7b6c 4g4f 6a6b 3g4e 3c2b 2e2d 2c2d 2h2d 8b8a B*6f P*2c 2d3d 5a4b 7f7e 7d7e P*7d
GCTのPVのinfo
info nps 226579 time 220676 nodes 50000582 hashfull 1000 score cp 10 depth 29 pv 7i8h 2b7g+ 8h7g 3a4b 2f2e 4b3c 3i3h 4a3b 3g3f 7a6b 6i7h 6c6d 5i6h 6b6c 9g9f 9c9d 6h7i 7c7d 3h3g 6c5d 3g4f 4c4d 3f3e 4d4e 3e3d 3c3d 4f3g B*3c 4i5h
dlshogiの方が、depthが高く探索の幅よりも深さを優先していることが分かる。
狭い局面に探索が集中して、その局面より先に後手番の読み抜けがあり先手に有利な評価をしている状況だと考えられる。
深さが優先されることは悪いことではないが、序盤の後手番に読み抜けがありそうなことが問題である。
GCTは学習にAobaZeroの棋譜を混ぜているため、序盤の局面が多く含まれている。
AobaZeroは、AlphaZeroと同様に初期局面から開始して、30手までは訪問数に応じた確率で選択している。
そのため、序盤の評価が安定していると考えられる。
対策
dlshogiは、強化学習の初期局面集に中終盤が多く含まれており、序盤の局面の比率が少ない。
そのため、序盤にうまく学習できていない局面がある可能性が高い。
AobaZeroの棋譜を混ぜて学習することが対策となっているが、AobaZeroの棋譜を使わなくてもdlshogiのみで学習できるようにしたい。
そのためには、dlshogiも、序盤から強化学習を行う必要がありそうだ。
AlphaZeroと同様に初期局面から30手までを確率的に選択するよりも、floodgateから出現頻度が一定以上の局面を初期局面とする方が効率が良く、現在のdlshogiの処理を変更しなくてよいため、floodgateから初期局面集を作成することにする。
現在のdlshogiは、初期局面集からランダムに局面を選択し、4手は確率的に選択している。
そのため、AlphaZeroと条件を合わせて、26手までの頻度が一定以上の局面を初期局面集とすることにする。
初期局面集を変えて、序盤の評価が正しくなるか別途検証する予定(強化学習には時間がかかるため結果がでるのはだいぶ先になる)。
2020/12/5 追記
floodgateから初期局面集を作成して、強化学習で使用するようにした。
先手後手どちらかのレーティングが3000以上で、手数が80手以上、千日手の棋譜は除外という条件で抽出した。
千日手を除外するのは、自己対戦で毎回千日手となる開始局面を除外したいためである。
抽出棋譜から、26手目までの出現頻度の統計を取り、99パーセンタイル以上の局面を対象とした。
ほとんどの局面は出現回数が1で、99パーセンタイルという条件でも、出現回数は、118591棋譜中で31回である。
https://github.com/TadaoYamaoka/DeepLearningShogi/blob/master/utils/csa_to_roots_hcp.py
2018年から2020年9月20日までのfloodgateの棋譜を入力として、実行した結果は以下の通り。
DeepLearningShogi\utils> python .\csa_to_roots_hcp.py -r F:\floodgate\a\ F:\hcp\floodgate26.hcp
num_games 118591
count ply
count 706460.000000 706460.000000
mean 4.363302 19.545299
std 207.161570 4.972049
min 1.000000 1.000000
25% 1.000000 16.000000
50% 1.000000 20.000000
75% 1.000000 24.000000
max 118591.000000 26.000000
th 31
output num 6933
count ply
count 6933.000000 6933.000000
mean 258.881437 14.571758
std 2075.449703 6.150281
min 32.000000 1.000000
25% 41.000000 10.000000
50% 60.000000 14.000000
75% 113.000000 19.000000
max 118591.000000 26.000000作成した初期局面集を使用して、自己対局を行ったところ、30手以内に高頻度で千日手となる局面が含まれていた。
学習データに偏りが生じるため、そのような局面は除くことにした。
30手で打ち切るようにして自己対局を多数行い、高頻度で千日手となる局面を削除した。
以前の初期局面集の活用
以前に使用していた中終盤を多く含む約5億局面の初期局面集は、モデルの学習中に実行する自己対局で使用することにした。
dlshogiでは、自己対局で500万~700万局面生成 → モデル学習 というサイクルを回しているが、モデル学習中にも学習に使用していないGPUで自己対局を行っている。
その際に以前の初期局面集を利用することにした。
ノイズなしの学習データ生成
また、強化学習時は、探索中のルートノードのポリシーにランダムでノイズを加えている。
そのため、生成される学習データは、ノイズを含んだデータになっている。
正確なValueの値を学習させるため、モデル学習中の自己対局ではノイズを加えないことにした。
モデル学習中に生成する局面の学習データ全体に対する割合は8.2%程度になる。
2020/12/8 追記
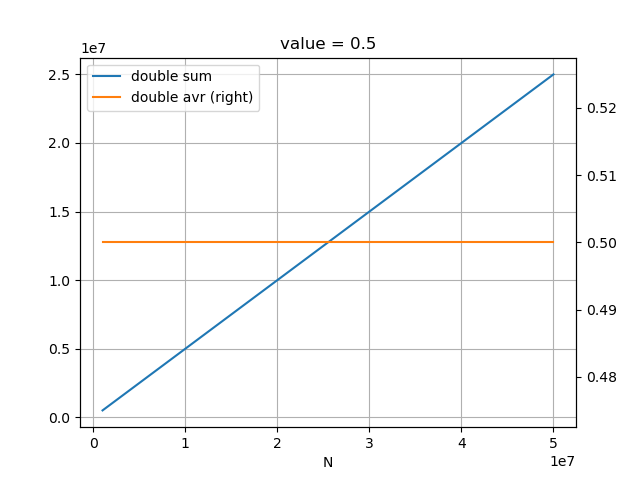
バックアップごとにvalueの値を累積していたため、floatの桁落ちが関係していそうということがわかった。
累積ではなく平均を都度計算する方式に見直す予定。
2020/12/12追記
定跡の評価値がおかしいのは、floatの桁落ちが原因であることが判明した。
将棋AIの進捗 その51(floatの桁落ち) - TadaoYamaokaの開発日記
dlshogiの強化学習を、上記の初期局面集で行った場合、約12%が重複データになることがわかった。
AobaZeroの前処理した棋譜も調べたところ、11.6%が重複データ局面になっていた。
hcpes = np.fromfile(r'F:/aobazero/hcpe/arch000015000000.hcpe', HuffmanCodedPosAndEval)
(len(hcpes) - len(np.unique(hcpes))) / len(hcpes)
Out[11]: 0.11643395063382735
序盤の局面から強化学習を行うと、データの偏りから序盤に偏って学習される懸念がある。
dlshogiの方では、方針を変えずに今までの多様な初期局面集を使い続けることにする。