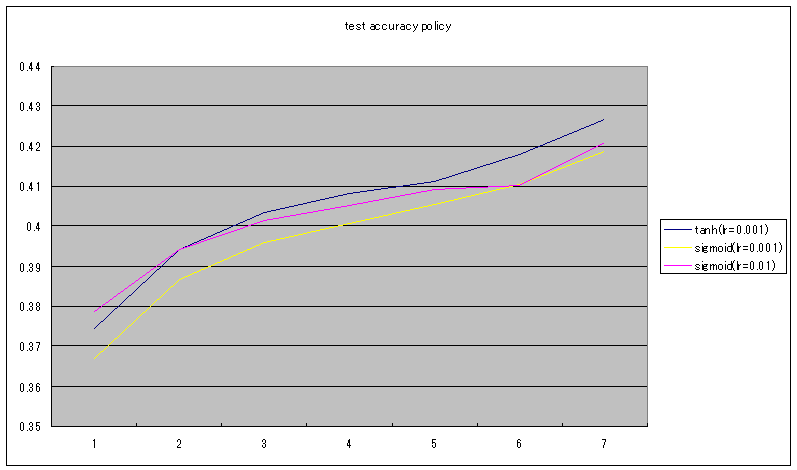
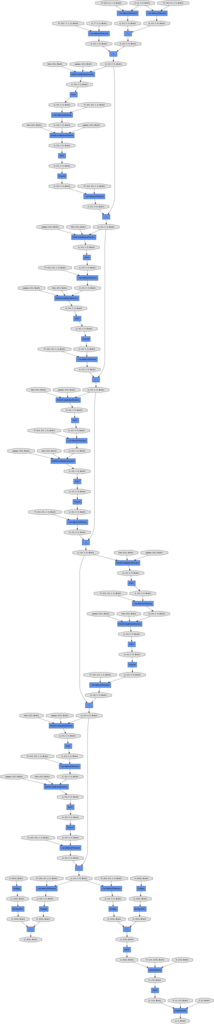
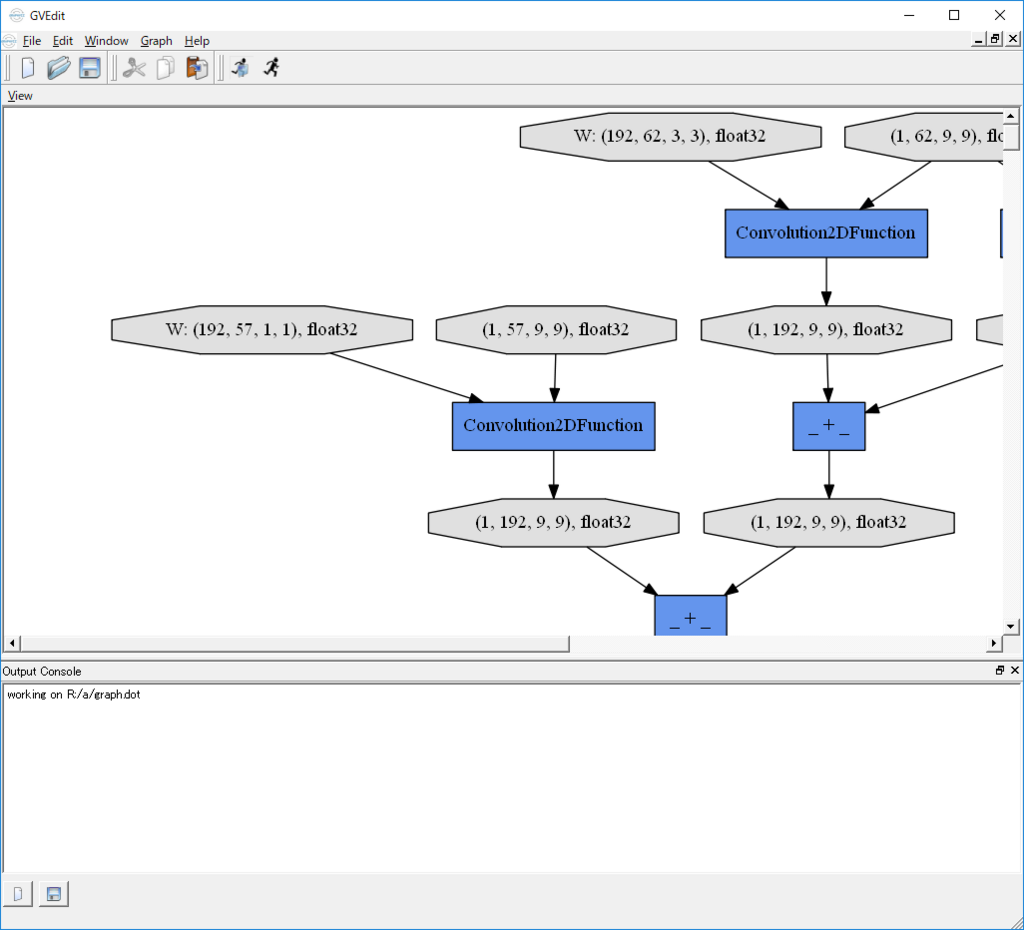
dotファイル出力
Visualization of Computational Graph — Chainer 7.8.1 documentation
このページの説明通り、モデルを構築し順伝播を実行し、出力のVariableを使用して、.dotファイルを作成する。
import numpy as np
from chainer import Variable
from chainer import Chain
import chainer.functions as F
import chainer.links as L
import chainer.computational_graph as c
FEATURES1_NUM=62
FEATURES2_NUM=57
MAX_MOVE_LABEL_NUM=101
k = 192
dropout_ratio = 0.1
fcl = 256
class PolicyValueNetwork(Chain):
def __init__(self):
super(PolicyValueNetwork, self).__init__(
l1_1_1=L.Convolution2D(in_channels = FEATURES1_NUM, out_channels = k, ksize = 3, pad = 1, nobias = True),
l1_1_2=L.Convolution2D(in_channels = FEATURES1_NUM, out_channels = k, ksize = 1, pad = 0, nobias = True),
l1_2=L.Convolution2D(in_channels = FEATURES2_NUM, out_channels = k, ksize = 1, nobias = True),
l2=L.Convolution2D(in_channels = k, out_channels = k, ksize = 3, pad = 1, nobias = True),
l3=L.Convolution2D(in_channels = k, out_channels = k, ksize = 3, pad = 1, nobias = True),
l4=L.Convolution2D(in_channels = k, out_channels = k, ksize = 3, pad = 1, nobias = True),
l5=L.Convolution2D(in_channels = k, out_channels = k, ksize = 3, pad = 1, nobias = True),
l6=L.Convolution2D(in_channels = k, out_channels = k, ksize = 3, pad = 1, nobias = True),
l7=L.Convolution2D(in_channels = k, out_channels = k, ksize = 3, pad = 1, nobias = True),
l8=L.Convolution2D(in_channels = k, out_channels = k, ksize = 3, pad = 1, nobias = True),
l9=L.Convolution2D(in_channels = k, out_channels = k, ksize = 3, pad = 1, nobias = True),
l10=L.Convolution2D(in_channels = k, out_channels = k, ksize = 3, pad = 1, nobias = True),
l11=L.Convolution2D(in_channels = k, out_channels = k, ksize = 3, pad = 1, nobias = True),
l12=L.Convolution2D(in_channels = k, out_channels = MAX_MOVE_LABEL_NUM, ksize = 1, nobias = True),
l12_2=L.Bias(shape=(9*9*MAX_MOVE_LABEL_NUM)),
l12_v=L.Convolution2D(in_channels = k, out_channels = MAX_MOVE_LABEL_NUM, ksize = 1, nobias = True),
l12_2_v=L.Bias(shape=(9*9*MAX_MOVE_LABEL_NUM)),
l13=L.Linear(9*9*MAX_MOVE_LABEL_NUM, fcl),
l14=L.Linear(fcl, 1),
norm1=L.BatchNormalization(k),
norm2=L.BatchNormalization(k),
norm3=L.BatchNormalization(k),
norm4=L.BatchNormalization(k),
norm5=L.BatchNormalization(k),
norm6=L.BatchNormalization(k),
norm7=L.BatchNormalization(k),
norm8=L.BatchNormalization(k),
norm9=L.BatchNormalization(k),
norm10=L.BatchNormalization(k)
)
def __call__(self, x1, x2):
u1_1_1 = self.l1_1_1(x1)
u1_1_2 = self.l1_1_2(x1)
u1_2 = self.l1_2(x2)
u1 = u1_1_1 + u1_1_2 + u1_2
h1 = F.relu(self.norm1(u1))
h2 = F.dropout(F.relu(self.norm2(self.l2(h1))), ratio=dropout_ratio)
u3 = self.l3(h2) + u1
h3 = F.relu(self.norm3(u3))
h4 = F.dropout(F.relu(self.norm4(self.l4(h3))), ratio=dropout_ratio)
u5 = self.l5(h4) + u3
h5 = F.relu(self.norm5(u5))
h6 = F.dropout(F.relu(self.norm6(self.l6(h5))), ratio=dropout_ratio)
u7 = self.l7(h6) + u5
h7 = F.relu(self.norm7(u7))
h8 = F.dropout(F.relu(self.norm8(self.l8(h7))), ratio=dropout_ratio)
u9 = self.l9(h8) + u7
h9 = F.relu(self.norm9(u9))
h10 = F.dropout(F.relu(self.norm10(self.l10(h9))), ratio=dropout_ratio)
u11 = self.l11(h10) + u9
h12 = self.l12(u11)
h12_1 = self.l12_2(F.reshape(h12, (len(h12.data), 9*9*MAX_MOVE_LABEL_NUM)))
h12_v = self.l12_v(u11)
h12_2 = F.relu(self.l12_2_v(F.reshape(h12_v, (len(h12_v.data), 9*9*MAX_MOVE_LABEL_NUM))))
h13 = F.relu(self.l13(h12_2))
return h12_1, self.l14(h13)
model = PolicyValueNetwork()
features1 = np.empty((1, FEATURES1_NUM, 9, 9), dtype=np.float32)
features2 = np.empty((1, FEATURES2_NUM, 9, 9), dtype=np.float32)
x1 = Variable(features1)
x2 = Variable(features2)
y1, y2 = model(x1, x2)
g = c.build_computational_graph([y1, y2])
with open('graph.dot', 'w') as o:
o.write(g.dump())