マンガの顔パーツ検出を試みているが、マンガの顔画像と検出点がセットになった教師データを大量に入手することができない。
自分で入力したデータで検出精度の実験を行って、ディープラーニングを使うことで、単一のコミックの画像であればかなりの精度で検出できることが検証できた。
しかし、他のコミックに対する汎化能力は低い。
ニューラルネットワークの構成をシンプルなものにしているので、教師データは少なくてすむはずなので、一つのコミックあたりの画像数を少なめにして、できるだけ多くのコミックの画像の検出点を手入力していくのが一つのアプローチだと思っている。
一方、より深いネットワーク構成で学習させることで、検出の精度を高めることができるはずだ。
そのためには、より多くの教師データが必要になる。
そこで、写真の顔器官検出の教師データが流用できないかと考えている。
写真の顔器官検出の教師データは、dlibのface_landmark_detection.pyのコメントに記載されているiBUG 300-Wのデータセットが入手可能である。
写真を線画化することでマンガの教師データとして使用できるかもしれない。
やってみなと分からないが、とりあえず線画化を行ってみた。
写真の線画化は、PhotoShopなどの画像処理ソフトに機能があるが、バッチ処理を行いたいためPythonで扱えるライブラリがないか探してみた。
OpenCVに線画化そのものの機能はないようだが、OpenCVで演算をしてやることで線画化ができるようだ。
www.mathgram.xyz
元はPaintsChainerの作者のコメント欄に記載されていた方法のようだ。さらに元をたどれば、画像編集ソフトを使って行われていたテクニック(参考)のようだ。
同じ方法で試してみた。
import cv2
import numpy as np
gray = cv2.imread('r:/indoor_295.png', cv2.IMREAD_GRAYSCALE)
neiborhood24 = np.array([[1, 1, 1, 1, 1],
[1, 1, 1, 1, 1],
[1, 1, 1, 1, 1],
[1, 1, 1, 1, 1],
[1, 1, 1, 1, 1]],
np.uint8)
dilated = cv2.dilate(gray, neiborhood24, iterations=1)
diff = cv2.absdiff(dilated, gray)
contour = 255 - diff
cv2.imwrite('r:/contour.png', contour)
変換元の写真

線画化

一部の線は強調されているが、はっきり線画化して欲しい顔が全体的にうっすらしている。
口は歯だけ線がはっきりして口の輪郭が分かりにくい。
これでは教師データとして使えなさそうである。
ガンマ補正
ガンマ補正を掛けて明るくしてから線画化した後、逆のガンマ補正をして元に戻してみる。
線画化は白領域を膨張(近傍の最大値をとる処理)させて元画像との差をとっているので、線画化前に白っぽくすることで線がくっきりする。
ガンマ補正はこちらのページを参考にした。
def gamma_compensation(img, gamma):
lookUpTable = np.zeros((256, 1), dtype = 'uint8')
for i in range(256):
lookUpTable[i][0] = 255 * pow(float(i) / 255, 1.0 / gamma)
return cv2.LUT(img, lookUpTable)
img_gamma = gamma_compensation(gray, 2.0)
dilated2 = cv2.dilate(img_gamma, neiborhood24, iterations=1)
diff2 = cv2.absdiff(dilated2, img_gamma)
contour2_tmp = 255 - diff2
contour2 = gamma_compensation(contour2_tmp, 0.5)
cv2.imwrite('r:/contour2.png', contour2)
変換後画像(ガンマ値=2.0→0.5)

全体的に線がくっきりして、口の輪郭もはっきりするようになった。
これでも、灰色で濃淡があるため、完全に線画にはなっていない。
なお、ガンマ値2.0と0.5のガンマ補正をグラフにすると以下のようになる。
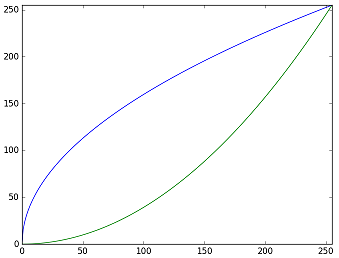
階調化するため、ガンマ値を極端に大きくしてみた。
変換後画像(ガンマ値=100.0→0.01)

濃淡は減っているが、線になってほしくない箇所が線になってしまった。
これならガンマ値=2.0の方がよさそうである。
今度は別の方法で薄い灰色の部分なくすために、コントラスト調整を行ってみる。
ガンマ値2.0でガンマ補正してから線画化した画像を、ガンマ値0.25で濃い目の線にした後、コントラスト調整で薄い部分を白に、線の部分を黒に近づける。
def contrast_adjustment(img, a, b):
lookUpTable = np.zeros((256, 1), dtype = 'uint8')
for i in range(256):
lookUpTable[i][0] = 255.0 / (1+math.exp(-a*(i-b)/255))
return cv2.LUT(img, lookUpTable)
contour2 = gamma_compensation(contour2_tmp, 0.25)
contour3 = contrast_adjustment(contour2, 10.0, 128)
cv2.imwrite('r:/contour3.png', contour3)

線が強調され、薄い灰色がなくなっている。
だいぶ線画に近づいた気がする。
なお、コントラスト調整のルックアップテーブルをグラフ化すると以下のようになる。
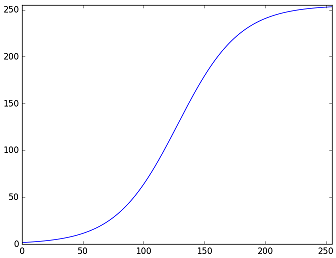
ガンマ値とコントラスト調整のパラメータは、画像によって最適な値が異なる。
他の画像で試すと別の値に調整しないとダメかもしれない。
ガンマ補正を掛けずに、コントラスト調整のみして線画化してみる。
img_contrast = contrast_adjustment(gray, 10.0, 128)
dilated4 = cv2.dilate(img_contrast, neiborhood24, iterations=1)
diff4 = cv2.absdiff(dilated4, img_contrast)
contour4 = 255 - diff4
cv2.imwrite('r:/contour4.png', contour4)

先にコントラスト調整をするとうまくいかないようだ。
写真の自然な線画化は難しい。
とりあえず使えるかわからないが、この線画化した画像を教師データに使用して試してみようと思う。





