将棋AIをChainerを使用した実装からcuDNNを使用した実装に変更できたので、マルチGPUでの性能を測定した。
Chainerを使用した場合
Python経由でChainerを使用しているPythonのGIL機構によってマルチスレッドの性能に制限がある。
Chainerを使用した場合の、マルチGPUによる効果は1.33倍程度であった。
|
playout/sec |
| シングルGPU(Titan V) |
5724 |
| マルチGPU(Titan V+GeForce 1080 Ti) |
7640 |
cuDNNを直接使用した場合
cuDNNを直接使用した場合の測定結果は、以下の通りであった。
|
playout/sec |
| シングルGPU(Titan V) |
6266 |
| マルチGPU(Titan V+GeForce 1080 Ti) |
10779 |
cuDNNを直接使用した場合、マルチGPU化により1.72倍の高速化の効果があった。
ChainerをシングルGPUで使用した場合と比べると、1.88倍になった。
棋力への影響
棋力にどれだけ影響しているかを確認してみた。
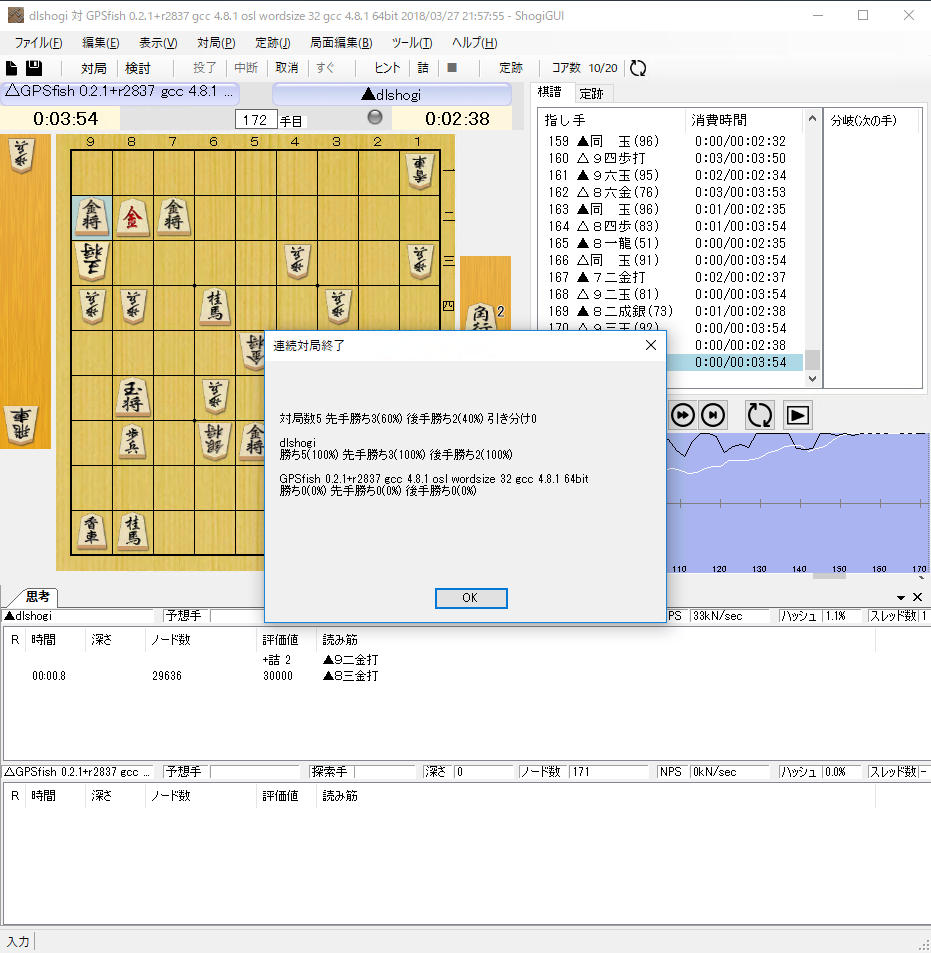
十分な対局数がこなせていないが、elmoで深さ8で生成した11億局面を学習したモデルで、GPSfishと1手3秒で5戦したところ、全勝だった。
CPUはCore i9 10コアなのでGPSfishに不利な条件ではない。
なお、GPSfishは定跡ありで、dlshogi側は定跡を使用していない。
シングルGPUのときは、GPSfishへの勝率は、40%程度だったので探索速度の向上によって棋力が上がっていそうである。
もっと対局数を増やして検証したい。
アピール文章書かないと・・・
2018/3/28 追記
48回連続対局を行ったところ、
dlshogi 36勝(75%) GPSfish 12勝(25%)
という結果だった。
cuDNNを使ったマルチGPU対応により、有意に強くなったことが確認できた。
GPSfishのeloレーティングを2800とすると、dlshogiのeloレーティングは2990.8となる。

探索の高速化は、まだ改良の余地があるので、もう少し高速化を行いたい。
自己対局による強化学習の方も、cuDNN対応を行う予定。