DeepMindがarXivで発表した、AlphaZeroからチェスの新しい概念を抽出して人間のパフォーマンス向上に使えるようにする方法について述べた「Bridging the Human-AI Knowledge Gap: Concept Discovery and Transfer in AlphaZero」を読んだ際のメモ。
概要
- AlphaZeroから隠されたチェスの知識を概念として抽出する
- 概念は、AlphaZeroの中間層から概念ベクトルとして抽出する
- 人間が知らずAlphaZeroだけが知っていること発見する
- 学習可能かつ新規な概念を抽出する
- 人間のグランドマスターが概念を学習可能か検証した
結果
- 概念と局面を提示することで、チェスのグランドマスターのテスト局面の正解率が向上した
- AlphaZeroが学習した知識は、人間の理解を超えるものではなく学習可能な知識であることが示された
詳細
導入
- 知識には、AIと人間の両方が知っていること(M∩H)、人間だけが知っていること(H-M)、AIだけが知っていること(M-H)がある
- 既存研究は主にM∩Hに焦点をあてているが、M-Hに焦点をあてる
- 正解が検証しやすいチェスを題材とする
- 4人のグランドマスターに概念を教えることができることを示す
- AlphaZeroの潜在表現を分析することでM-Hが存在することの証拠を発見する
- AlphaZeroの方策ネットワークとMCTSツリーを使用する
- 新規性と教育可能の観点でフィルタリングする

概念の定義
概念の発見方法
- 凸最適化を使用して AZ の概念を表すベクトルを発掘する
- 教えやすさと新規性に基づいて概念をフィルタリングする
概念ベクトルの発掘
- 概念発見を凸最適化問題として定式化
- 最小性は、L1ノルムを通じてスパース性を促進することによって達成する

ここで、 は概念 c を表すために層 𝓁 の潜在空間に存在するベクトル、
は層 𝓁 の次元
- 静的概念と動的概念で概念制約が異なる
- 静的概念は単一の状態で見られるように定義される
- 動的概念は一連の状態で見出されるように定義される
静的概念の概念制約
- 静的概念は、単一の状態のみを含む概念として定義
- 局面にラベル(概念cを含むか含まないか)付けされた教師ありデータを使用
- 教師ありデータの概念は人間の知識をコード化しているので検証できる
- 正例と負例を使用して潜在表現(ニューラルネットワーク内の活性化の後の表現)を生成
- 概念を含む方が、潜在表現と概念ベクトルの内積が大きいという仮説を立てる
- 以下の通り凸最適化問題を定式化
![]()
ここで、は正例の層𝓁の潜在表現、
は正例の層𝓁の潜在表現
- ホールド分割したテストセットで評価できる
動的概念の概念制約
- 動的概念は、一連の状態に見られる概念として定義
- モンテカルロ木探索 (MCTS) 統計を使用して、意味のある状態シーケンスの候補を見つける
- 最適なロールアウトと途中の標準以下のロールアウトを対比する
- MCTSの価値推定値または訪問数に従って最適でないパスと定義する
- 概念cにより、最適なパスが選択されたと仮定
- 3つの異なる説明
- シナリオ1 積極的な計画: ロールアウトにより概念が増加させる
- シナリオ2 予防計画: ロールアウトにより概念の存在が回避される
- シナリオ3 両方のロールアウトに存在する概念
- シナリオ1と2に関心がある
- シナリオ1は、以下の通り凸最適化問題を定式化

ここで、Tはロールアウトの深さ
- シナリオ2では不等式が反対になる

- 最適なパスを、さまざまな MCTS 深度にわたる複数の標準以下のパスと対比
- 複数の標準以下のパスを使用することで多意味ベクトルを学習する可能性を減らし、解空間をさらに縮小する
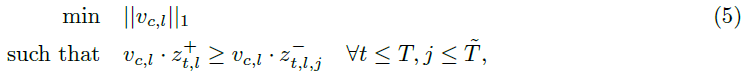
ここで、は最適ではないロールアウトが見つかる最大の深さ
概念のフィルタリング
- 抽出できた概念には、多くは既知の概念または一般化できない概念を含む
- 有用(転移可能)で新規なものにフィルタリングする
教えやすさ
- 概念を別のエージェント教えてタスクを解決できるか
- アイディア
- フェーズ1: ベースラインとなる概念を知らないエージェント(方策のトップ1の重複が0.2 未満)を見つける
- フェーズ2: 概念プロトタイプ(概念を例示するサンプル)を使用してエージェントに概念を教える
- フェーズ3: 概念に関連するタスクでパフォーマンスを評価する
- 概念が教育可能であればフェーズ3でパフォーマンス向上が期待される
- 人間とのアプローチを評価するときも、同様のプロセスを使用して評価
- フェーズ2では、AlphaZeroを教師とする
- プロトタイプの選択
- 学習は、教師(AlphaZero)の方策と生徒の方策のKLダイバージェンスを最小化
- 評価は、トップ1の手を選択する頻度で評価
- AlphaZeroの対局からランダムにサンプリングして学習場合と比較する
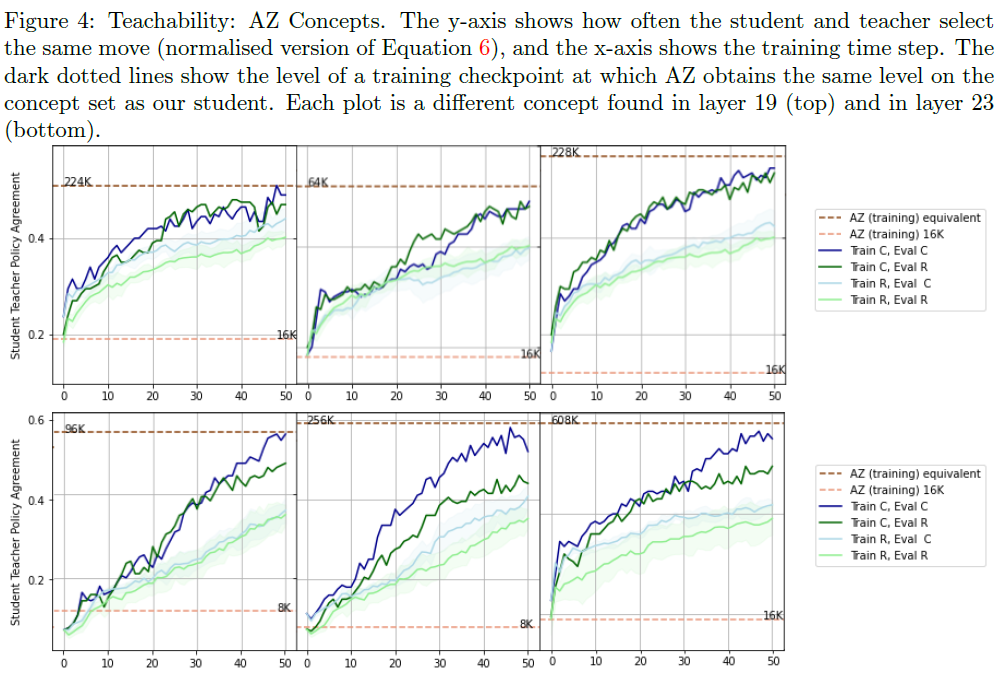
- 概念プロトタイプで学習すると(濃い線)、ランダムなプロトタイプで学習する(薄い線)より大幅にパフォーマンスが向上する
新規性
- アプローチ
- AlphaZeroの訓練の後期段階で学習される概念を見つける
- 新規性の指標に基づいて概念をフィルタリングする
- 概念は、AlphaZeroの訓練の後期段階で学習される
- 最新と、75 Elo ポイントが異なるバージョンの AlphaZero を使用
- 意見が一致しないチェスの局面を選択
- 検証は、AlphaZeroのゲームで発生し、人間のゲームでは発生しないかどうかで判断
- 概念をAlphaZeroのゲーム ベクトル空間と人間のゲーム ベクトル空間に回帰することによって新規性スコアを測定

人間による評価
- グランドマスターによる人間の評価は、教えやすさの測定方法と同様に3 つの段階に従う
- フェーズ1: 概念に対応する一連のパズルで、ベースラインのパフォーマンスを測定
- フェーズ2: フェーズ1と同じパズルを、AlphaZeroの推奨手と合わせて提示
- フェーズ3: 概念に対応する未見のパズルで、最終パフォーマンスを測定
- 4人のグランドマスターが評価に協力
- 3~4つの概念に対する 4 つのパズル (概念ごとに)を提示
- 一部重複があったが、異なる参加者には異なる概念が示された
グランドマスターのパフォーマンス

- すべての参加者がフェーズ1 と 3 の間で顕著に改善
- 向上の大きさは、チェスプレイヤーの強さ(Elo レーティング)とは相関しない
- パフォーマンスに影響を与えた可能性のある要因
- 難易度と品質のばらつき
- 教えやすさのばらつき
- 熟考の結果: 自由形式のコメントでAlphaZeroの戦略に言及しているが最終的に選択しなかった
概念の定性分析
- 全体として、グランドマスターは概念を高く評価
- アイデアにはしばしば新しい要素が含まれていることを発見
- 局面が非常に複雑であることに気づいた
- 人間がラベル付けしたコンセプトを使用してグラフ分析することで概念の意味について洞察できる

- エッジの重みが最も大きい2つの概念
- 空間: 空間を増やすことが計画の重要な要素
- 奪還: 駒を取り戻す/獲得する計画
学習に失敗した例
- 駒損するにも関わらず、空間の優位性を獲得するプレイ
- パズルの証拠からグランドマスターがこの概念を学ばなかったことを示唆している
- 人間はこれらの概念に異なる優先順位を付ける傾向がある(できるだけ早く王を安全な場所に連れて行くことを優先するなど)
人間とAlphaZeroの違い
- 定性的な例は、AlphaZeroがチェスの局面における概念の関連性に関して人間とは異なる事前条件を持っていることを示唆
- 人間のチェスプレイヤーは、ヒューリスティックなチェスの原則を採用する
- 一例は、オープニングの 3つの「黄金律」(センターをコントロールし、自分の駒を展開し、キングを安全な場所に連れて行く)
- AlphaZeroは前提知識を持っていないため、より柔軟になることができる
- AlphaZeroは特定のサイドに集中するのではなく、ボード全体でプレイする
- 駒の価値はあまり重要視せず、空間と駒のアクティビティを優先する
- 人間は他の人間とチェスをするため、情報の非対称性と不完全なプレイを想定する可能性がある
- 人間は、対戦相手が間違いを犯すことを期待して、チェスの局面を複雑にしたり、最良の手があまり明確ではない継続を選択することがある
- AphaZeroと人間では時間の役割が違う
- 人間はできるだけ早く勝利を確実にし、リスクを最小限に抑えようとして、チェスの局面を単純化することがある
- AlphaZeroは勝つことだけを目標に訓練しているため、戦略的に遅い勝利を選択することがある
結論
感想
将棋の世界では、棋士の間でAIは評価値は教えてくれるが、なぜ最善かは教えてくれないと言われている。
AIで「なぜ」に答える方法について関心があり、この論文を見つけたので読んでみた。
人間に理解できる自然言語で「なぜ」に答えるのが理想だと思うが、この論文は、AlphaZeroが学習している概念をベクトルとして抽出して、そこから概念を表す局面を例示することで、人間が学習できることを示している。
だだし、例示で学習できる人間はチェスのトッププレイヤーに限られると思うので、普通の人間でも理解できように自然言語で答えるにはまだハードルがあると思う。
概念を、既知のチェスの概念と関連付けることで、分析できるように試みているので、この手法を発展されることで言語化は可能かもしれない。
この論文では人間が知らない新規の概念に焦点をあてているが、既知の概念を表す局面を抽出する手法として使えるので、初心者が既知の概念を練習するための問題集の作成方法としても使えそうである。
まとめ
AlphaZeroから、チェスの学習可能な新規の概念を抽出する方法に関する論文を読んだ。
概念をベクトルとして抽出して関連する局面を例示することで、人間に学習可能であることを示している。
チェスのグランドマスターが協力して、パフォーマンスが向上できることを検証している。
将棋でも、この手法でdlshogiの概念を抽出して、人間が学習可能か興味があるので、試してみたい。