前回、将棋AIのモデルにLoRAを適用して、人間プレイヤーの傾向を学習できることを確かめた。
今回、LoRAが通常の追加学習と比較して効率的か比較してみた。
また、序盤、中盤、終盤で傾向に違いがあるか検証してみた。
追加学習と比較
事前学習済みモデルに人間プレイヤーの棋譜を追加学習した場合と比較した。
条件
- 学習率、エポックは同一
- 方策のみ学習
結果
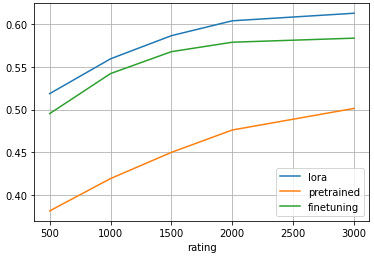
※凡例:finetuningが追加学習、pretrainedは事前学習済みモデル
追加学習により、事前学習済みモデルより10%ほど一致率が高くなっている。
LoRAと追加学習を比較すると、LoRAの方が2%ほど一致率が高い。
LoRAの方が効率的に人間プレイヤーの傾向を学習できている。
序盤、中盤、終盤
序盤、中盤、終盤で傾向に違いがあるか確認した。
条件
- 40手未満を序盤、40手以上80手未満を中盤、80手以降を終盤とする
- 序盤、中盤、終盤ごとに指し手の一致率を計測
結果
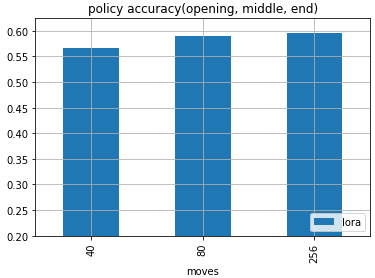
※x軸:40が序盤、80が中盤、256が終盤
LoRAで学習したモデルの一致率は、序盤と比べて、中盤、終盤の一致率が高い。
中盤と終盤はわずかに終盤の方が高い。
序盤は、人間プレイヤーの戦型が多様であるため、一致率が下がっていると考えられる。
序盤よりも中盤以降の一致率が高いことから、序盤の定跡を学習しているだけではなく人間プレイヤーの傾向を学習できていると言えそうである。
LoRA、事前学習済みモデル、通常の追加学習の比較
事前学習済みモデルと通常の追加学習したモデルでも確認してみた。

事前学習済みモデルは、序盤と中盤以降の差が大きい。
序盤の一致率が低いのは、AIの指し手は戦型が偏っているのに比べて人間の戦型が多様なためと考えられる。
まとめ
LoRAを適用することで、通常の追加学習と比較して効率的に人間プレイヤーの傾向を学習できることが確認できた。
また、序盤、中盤、終盤では、序盤と比べて中盤以降の一致率が高いことがわかった。
序盤の定跡を学習しているだけではなく、人間プレイヤーの傾向を学習できていることが確認できた。