この議事の内容は古いです。現在この手順では動きません。
Stable Diffusionが公開されて一週間もたたないうちに便利なUIがいくつもリリースされている。
その中でも、stable-diffusion-webuiが機能が充実している。
GitHub - hlky/stable-diffusion-webui: Stable Diffusion web UI
ということで、stable-diffusion-webuiをローカルPCのWindows11のWSL2上で動かせるようにした。
以下、構築手順を示す。
Conda環境とPyTorchの構築は、前回の記事の内容と同じである。
なお、後々バージョン不整合が起きたため、前回の記事の内容を修正している。
WSL2上にconda環境作成
WSL2のUbuntu 20.04上に環境構築する。
wget https://repo.anaconda.com/archive/Anaconda3-2022.05-Linux-x86_64.sh
sh Anaconda3-2022.05-Linux-x86_64.sh
conda環境作成
conda環境を作成する。
conda create -n stable-diffusion python=3.9
conda activate stable-diffusion
PyTorchインストール
PyTorchをインストールする。
conda install pytorch torchvision torchaudio cudatoolkit=11.6 -c pytorch -c conda-forge
Jupyterとpandas、matplotlibをインストールする。バージョン不整合を避けるためにconda-forgeからインストールする。
conda install jupyter pandas matplotlib -c conda-forge
必須ライブラリインストール
Stable Diffusionおよびstable-diffusion-webuiで必要となるライブラリをインストールする(scipyをcondaでインストールすると不整合が起きたのでpipでインストールしている)。
pip install diffusers transformers scipy ftfy invisible-watermark gradio pynvml omegaconf pytorch_lightning
pipにないパッケージインストール
k-diffusion
k-diffusionをgitからインストールする。
pip install git+https://github.com/crowsonkb/k-diffusion/
taming-transformersをソースからインストールする(pipからインストールできるパッケージでは動作しない)。
cd ~
git clone https://github.com/CompVis/taming-transformers.git
cd taming-transformers
pip install -e .
stable-diffusionのソースインストール
cd ~
git clone https://github.com/CompVis/stable-diffusion.git
stable-diffusion-webuiのソースインストール
cd ~
git clone https://github.com/hlky/stable-diffusion-webui.git
stable-diffusionのソースディレクトリにコピーする。
cd stable-diffusion-webui
cp -r * ../stable-diffusion/
モデルダウンロード
Stable Diffusionのモデルをgithubからダウンロードする。
git lfsを使用するため、セットアップしていない場合は、セットアップする。
sudo apt install git-lfs
git lfs install
リポジトリをクローンする。
cd ~
git clone https://huggingface.co/CompVis/stable-diffusion-v-1-4-original
cloneにはHuggingfaceのアカウントが必要になる。
モデルのチェックポイントのシンボリックリンクをstable-diffusionのソースディレクトリに作成する。
cd stable-diffusion/models/ldm/stable-diffusion-v1
ln -s ~/stable-diffusion-v-1-4-original/sd-v1-4.ckpt model.ckpt
stable-diffusionのパッケージインストール
cd ~
cd stable-diffusion
pip install -e .
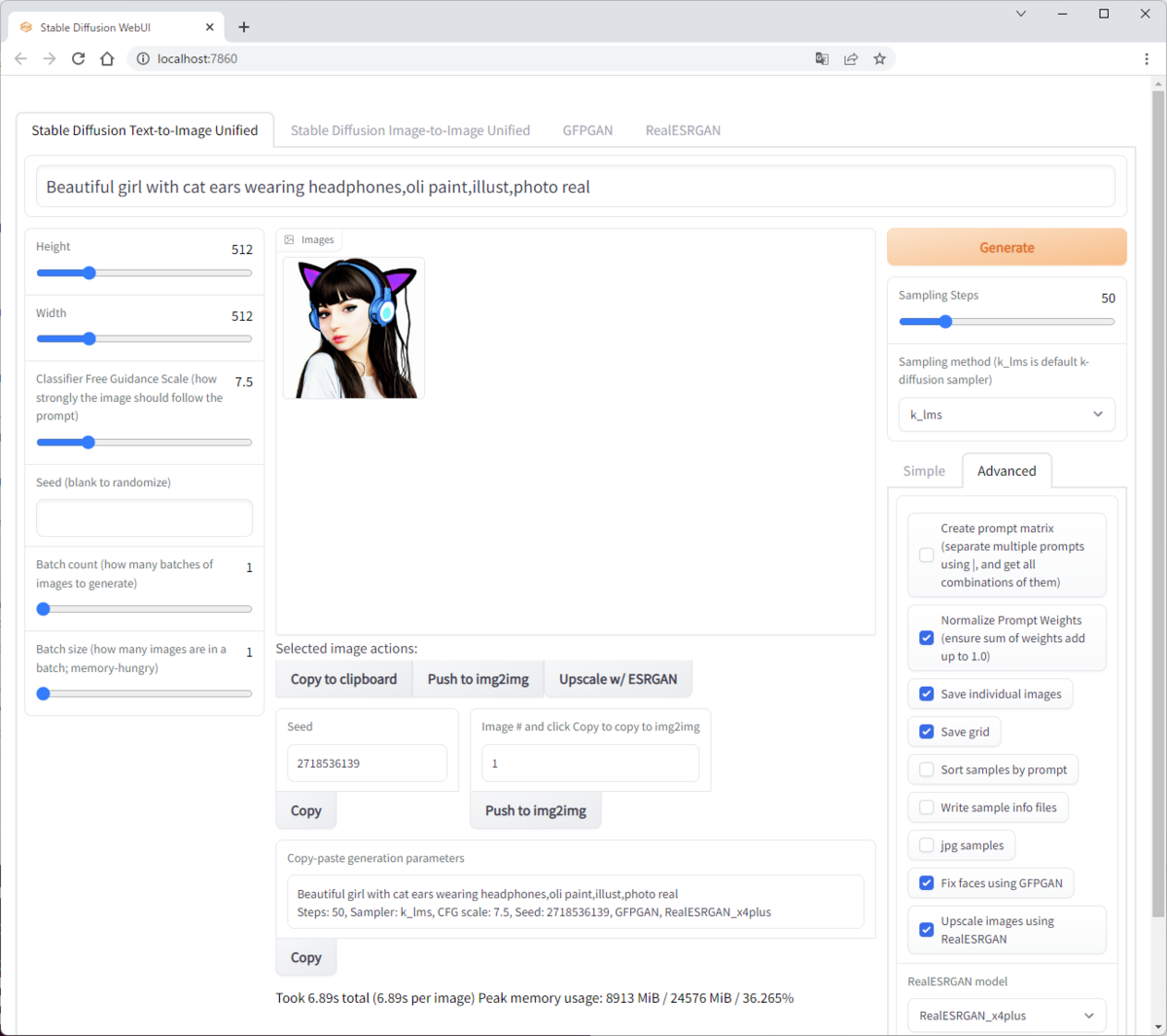
stable-diffusion-webuiの起動
stable-diffusion-webuiを起動する。
python webui.py
初回は、各種ファイルのダウンロードが入るため、起動までに数分かかる。
Loading model from models/ldm/stable-diffusion-v1/model.ckpt
Global Step: 470000
LatentDiffusion: Running in eps-prediction mode
DiffusionWrapper has 859.52 M params.
making attention of type 'vanilla' with 512 in_channels
Working with z of shape (1, 4, 32, 32) = 4096 dimensions.
making attention of type 'vanilla' with 512 in_channels
Downloading vocab.json: 100%|█████████████████████████████████████████████| 939k/939k [00:00<00:00, 987kB/s]
Downloading merges.txt: 100%|█████████████████████████████████████████████| 512k/512k [00:00<00:00, 646kB/s]
Downloading special_tokens_map.json: 100%|██████████████████████████████████| 389/389 [00:00<00:00, 446kB/s]
Downloading tokenizer_config.json: 100%|████████████████████████████████████| 905/905 [00:00<00:00, 905kB/s]
Downloading config.json: 100%|█████████████████████████████████████████| 4.31k/4.31k [00:00<00:00, 3.62MB/s]
Downloading pytorch_model.bin: 100%|███████████████████████████████████| 1.59G/1.59G [00:32<00:00, 52.2MB/s]
/home/kei/anaconda3/envs/stable-diffusion/lib/python3.9/site-packages/gradio/deprecation.py:43: UserWarning: You have unused kwarg parameters in Button, please remove them: {'full_width': True}
warnings.warn(
Running on local URL: http://localhost:7860/
To create a public link, set `share=True` in `launch()`.
まとめ
stable-diffusion-webuiの実行環境をローカルPCで構築する手順について記載した。
GFPGANとRealESRGANの設定を行うと、顔の修正などさらに高度なことができる。
そちらの設定手順は、別途記載したい。