前回、PaintsChainerをPyTorchにポーティングして着色モデルの学習を行った。
その際、danbooru2017の512x512の画像をすべて使用したが、四コマ漫画のようなイラスト以外の画像も含んでいたため、学習の妨げになっていた可能性があるため、今回は、画像をフィルタをしてイラストに絞って学習した。
また、前回は、128x128の着色モデルの学習のみ試したが、512x512への超解像度モデルの学習も試した。
データセットのフィルタリング
danbooru2017の512x512の画像には、イラスト以外の4コマ漫画のような画像も含んでいる。
Stable Diffusionでは、CLIP aesthetic scoreで、画像の審美を採点してフィルタリングをしている。
Waifu Diffusionでは、danbooruのデータセットを、独自に構築したaestheticモデルでフィルタリングしている。
Waifu Diffusionと同じdanbooruのデータセットを使用しているため、Waifu Diffusionのaestheticモデルを使用した。
また、グレースケールは除外しているが、グレースケール以外の単色のイラストも含まれているため、画像のカラフルネスでもフィルタリングを行った。
カラフルネスの採点には、こちらのサイトのコードを使用した。
Computing image “colorfulness” with OpenCV and Python - PyImageSearch
Waifu Diffusionのaestheticモデルの採点0.1以上、カラフルネス10以上という条件でフィルタリングした結果、元のデータ数(288914)の約半分(138341)になった。
着色モデルの学習
フィルタリングしたデータセットで着色モデルを学習し直した。
フィルタリング前は、50エポック学習したので、倍の100エポックした。
100エポック学習した時点の損失は以下のようになった。

着色画像の例
スケッチ

前回のモデル
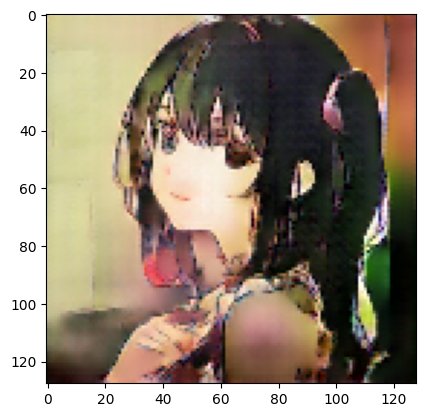
今回のモデル
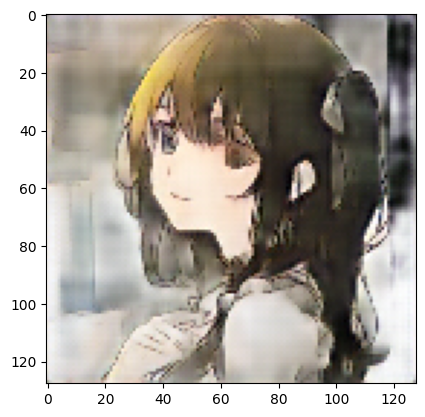
エポックごとに着色の質が変わって安定しないが、最終エポックでは、淡い着色となった。
前回に比べると質が良くなったかは分からない。
超解像度モデルの学習
前回は超解像度モデルの学習は試さなかったが、今回は超解像度モデルの学習も行った。
13エポック学習した時点の損失は以下のようになった。

着色例

着色モデルの最終エポックが淡い着色になったため、超解像度モデルの結果も淡い着色になった。
顔と髪の着色は比較的自然な着色になっているが、手の色は白っぽくなってしまった(カラーヒントを与えることで半手動で改善はできるはずである)。
まとめ
danbooru2017データセットをカラフルなイラストにフィルタリングしてPyTorchにポーティングしたPaintsChainerの学習を試した。
また、超解像度モデルの学習も行った。
結果、淡い着色だが、部分的には比較的自然な着色ができるモデルが学習できた。
GANの学習は安定せず、エポックごとに着色の傾向が大きく変わる傾向があった。
ベストな着色のモデルを学習しようとした場合、複数回実験して、自然な着色ができた時点のモデルを選定する必要がある。
今回使用したデータセットは、アスペクト比が正方形でない場合、黒でパディングされているため学習に悪い影響を与えている可能性がある。
アスペクト比の影響を除くには、Novel AIで使われていたようなAspect Ratio Bucketingが有効と考える。
ただし、PaintsChainerのDiscriminatorは解像度に依存するモデルのため、出力層を全結合ではなくGlobal Average Poolingにするなど変更が必要になる。
イラストのデータセットの扱いに慣れてきたので、次は、拡散モデルの着色モデル の学習を試したい。