AobaZeroの棋譜を利用するにあたり、統計的な傾向を把握しておきたいと思い調べてみた。
調査範囲
arch000012000000.csa.xz ~ arch000026050000.csa.xzの棋譜を調べた。
1ファイル当たり1万棋譜含まれ、棋譜数は合計で14,050,000になる。
手数
手数を10手間隔のヒストグラムにした(100万棋譜単位の積み上げ)。

※系列のgroupは棋譜は棋譜のファイル名の数値部分の100万で割った値
120手あたりにピークがある。
新しい棋譜ほど手数がわずかに短くなる傾向がある。
終局状況
投了、千日手、入玉宣言勝ち、最大手数で中断、反則の数を、100万棋譜単位の積み上げグラフにした。
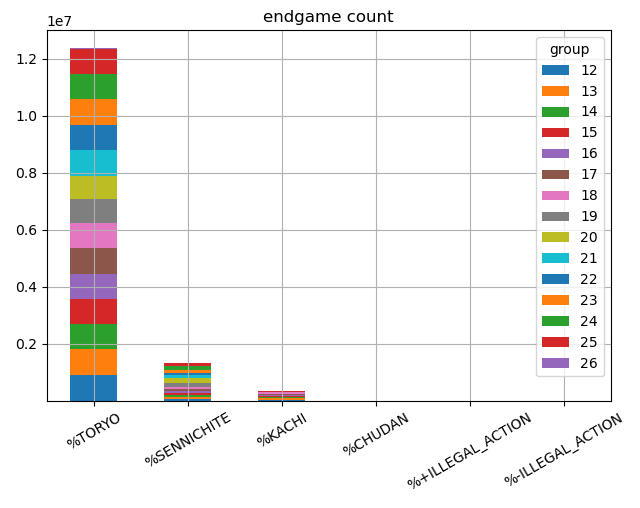
| 終局状況 | 合計 | 割合 |
|---|---|---|
| %TORYO | 12382954 | 88.13% |
| %SENNICHITE | 1337706 | 9.52% |
| %KACHI | 325071 | 2.31% |
| %CHUDAN | 1149 | 0.01% |
| %+ILLEGAL_ACTION | 2175 | 0.02% |
| %-ILLEGAL_ACTION | 945 | 0.01% |
88%が投了で終局している。
最大手数(512)で引き分けの数はほとんどなかった。
入玉宣言勝ちの数

arch000019000000あたりから大きく傾向が変わっている。
これは、AobaZeroのバージョンアップで、勝率10%で投了するようにしたことが原因と思われる。

詰みの見逃しの数
AobaZeroは簡単な詰みを見逃す傾向がある。
どれくらい見逃しているか確認した。
1万棋譜ごとの5手詰めを見逃した数を時系列で調べた(50手以上の棋譜を調査)。
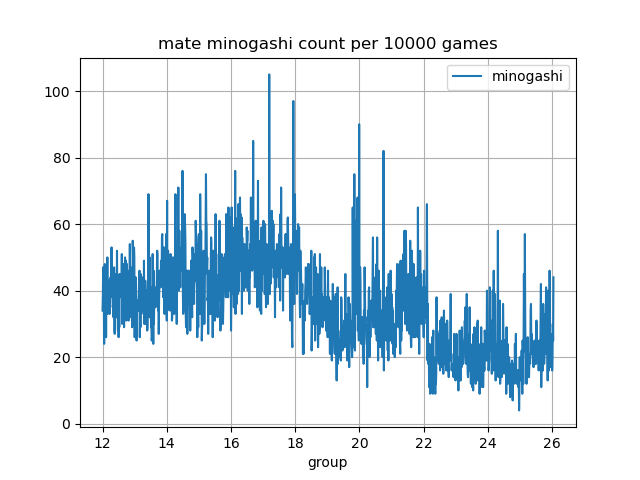
arch000019000000あたりから減っているのは、投了の閾値が原因と思われる。
arch000022000000あたりからさらに減っているのは、投了の勝率が自動調整になったからだと思われる。
手数が50手以上の棋譜で、見逃しは投了扱いとした場合の、各終局状況の数と詰みを見逃して逆転した数の合計は以下の通り。
| 終局状況 | 合計 | 割合 |
|---|---|---|
| 投了 | 10948372 | 87.19% |
| 千日手 | 1286463 | 10.24% |
| 入玉宣言勝ち | 321708 | 2.56% |
| 中断 | 532 | 0.00% |
| 詰み見逃しで逆転 | 49228 | 0.39% |
0.39%の棋譜で5手詰みを見逃して逆転が発生している。
まとめ
AobaZeroは入玉宣言勝ちを目指す棋風に特徴がある。
棋譜を調べた結果、入玉宣言勝ちの棋譜は、全体の2.31%含まれていた。
dlshogiの自己対局では、初期局面集を使っているため直接比較できないが、直近の90456対局で調べたところ、0.46%である。
dlshogiと比べると、入玉宣言勝ちの棋譜の割合は多い。
入玉宣言勝ちの初期局面集を作ったり、入玉宣言の学習に、AobaZeroの棋譜は利用価値が高い。
ただし、arch000019000000あたりから大幅に数が減っているので、それ以前の棋譜から抽出が必要である。
(投了の閾値がない方が入玉宣言勝ちの棋譜が増えて利用価値が大きかったので戻して欲しい・・・(個人的感想))
一方、AobaZeroは、詰まして勝つ将棋には弱い傾向がある。
棋譜を調べたところ、0.39%の棋譜で5手詰めを見逃して逆転していた。
(※はじめ55%と記したが、逆転が条件になっていなかったため修正した。)
調査に使ったソース
DeepLearningShogi/aoba_to_hcpe2.py at feature/hcpe2 · TadaoYamaoka/DeepLearningShogi · GitHub
グラフ化のソース
import pandas as pd df = pd.read_csv('stat.csv') df['group'] = df['name'].apply(lambda x: x[8:10]) df.groupby('group')[[str(i) + '.0' for i in range(0, 520, 10)]].sum().T.plot.area(grid=True) plt.xticks(range(0, 52, 5)) df.groupby('group')[['%TORYO', '%SENNICHITE', '%KACHI', '%CHUDAN', '%+ILLEGAL_ACTION', '%-ILLEGAL_ACTION']].sum().T.plot.bar(stacked=True, grid=True) df[['group', '%KACHI']].plot(x='group', grid=True) df[['group', '%SENNICHITE']].plot(x='group', grid=True) df[['group', 'minogashi']].plot(x='group', grid=True)