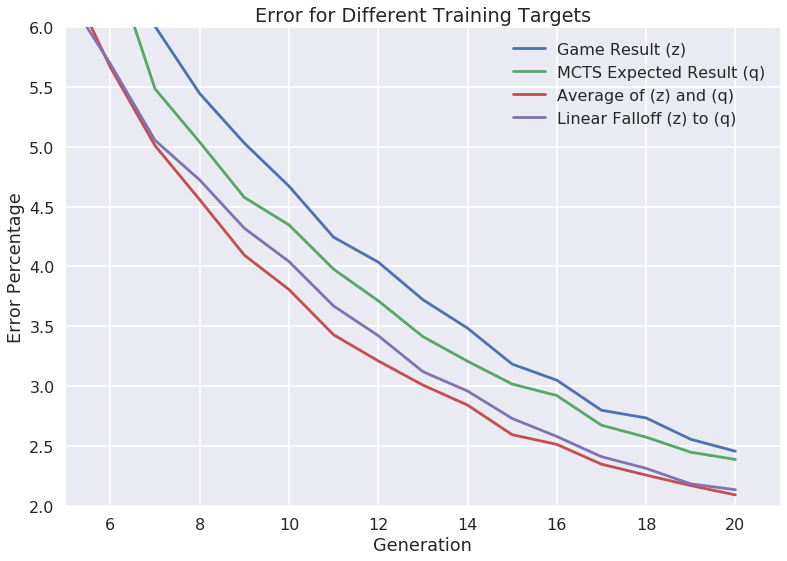
この記事で、AlphaZeroの再実装を試した際に、価値関数の学習目標をゲームの結果からQ値に変更することで、エラー率が低下するという報告がされています。
medium.com
ゲームの結果とQ値の平均を目標とするとさらにエラー率が低下し、ゲームの結果からQ値に段階的に変更することでさらにエラー率が低下しています。
Q値について
Q値には、シミュレーションをおこなった後の、ルートノードにバックアップされた価値の平均が使用されています。
考察
ゲームの結果だけでなく、探索の評価値から予測した勝敗を学習目標とする考え方は、コンピュータ将棋の学習でもelmoが導入して以来、普及しています。
実際の結果の推定値を使用して学習する方法は、ブートストラップ法とも呼ばれています。
私が開発しているdlshogiの強化学習でも、価値関数の学習に、ゲームの結果とシミュレーション後のルートノードのQ値の平均を使用しています。
ただし、Q値は、最善応手にバックアップされた価値の平均としています。
第 28 回世界コンピュータ将棋選手権dlshogiアピール文章
私も以前に、価値関数の学習にブートストラップ法が効果があることを確認していましたが、実験数が少なく客観的な検証はできていませんでした。
上記の記事の実験では、AlphaZero方式の学習でもブートストラップ法が有効であることが実験で示されています。
dlshogiでは、AlphaZeroの学習はGoogleのマシンパワーがないと不可能と思われていますが、学習の工夫で個人レベルでもなんとかなることを示せたら良いと思っています(できるかどうかはわかりませんが・・・・)。
