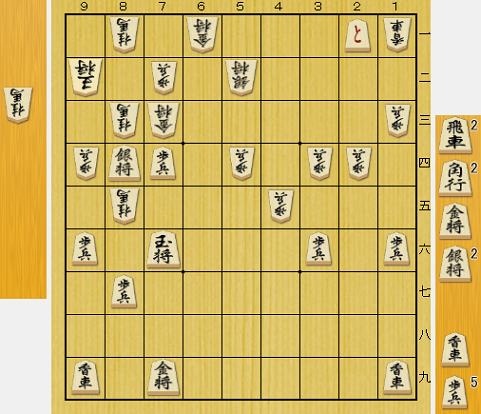
df-pnの検証のために、詰みの局面でテストしていたが、やねうら王では詰みと出る局面で不詰みの判定になる局面があった。
調べてみると、次のような王手でない局面で、相手がどんな手を指しても次の王手で詰みとなる局面だった。

df-pnの指し手生成に王手のみという条件を入れてしまうと、こういう局面が正しく判定できなくなる。
しかし、連続王手以外を探索に含めてしまうと、df-pnの中間ノードでのpnとdnの値がほとんど無意味になってしまうので、探索空間が膨大になってしまう。
これを解決しないと、df-pnを実戦の局面で使うのは厳しそうです。
詰みの探索は、モンテカルロ木探索の末端ノードでの数手の探索のみして、ルート局面での探索はαβ+評価関数で行った方が良い気がしてきました。
ということで、実装までしておきながらdf-pnは不採用ということにしようと思います。
追記
15手で1秒はかかりすぎとTwitterでコメントを頂いたので、なのは詰めで測定してみました。
42msでした。早いですね。自分のはdf-pnの素朴な実装ですが、ここまで差があるとは思いませんでした。
— 山岡忠夫 (@TadaoYamaoka) 2017年9月26日
結果は、42ms。
自分の実装は、少し無駄があったので、修正しても1088msです。
なのは詰めはpnとdn以外のヒューリスティックを採用しているようなので、その差がでているようです。
42msだと末端ノードで呼び出しても良いくらいですね。
2017/9/27 追記
ループを適切に処理していないのが遅い原因の一つかと思い、ループしている数をカウントしてみました。
結果、24,523ノードでした。
全探索ノードが1,158,018だったので、連結したノード数は2%程ですが、ループしたノードの下のノードも調べることになるので、かなりの無駄が発生していると思われます。
長手詰めの性能を上げるには、ループの対処が必要そうです。
追記 必死を含めた詰み探索の必要性について
おそらくαβで探索しているプログラムの場合、必死を含めた詰み探索までする必要はないです。
モンテカルロ木探索の場合、有利な局面だと手を緩めて無駄に長い手順になることがあるので、必死を含めた詰み手順を求めたいという動機があります。